// Lab 01 · Neo4j
Создание графа
Цель: создать граф из 5 узлов и 7 связей в Neo4j с помощью языка Cypher.
01
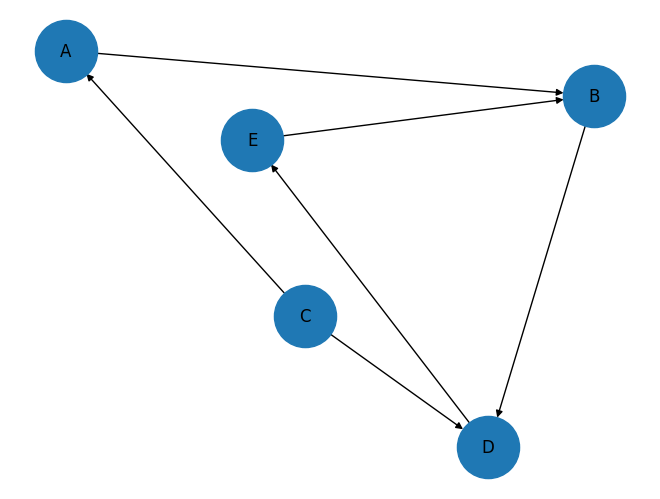
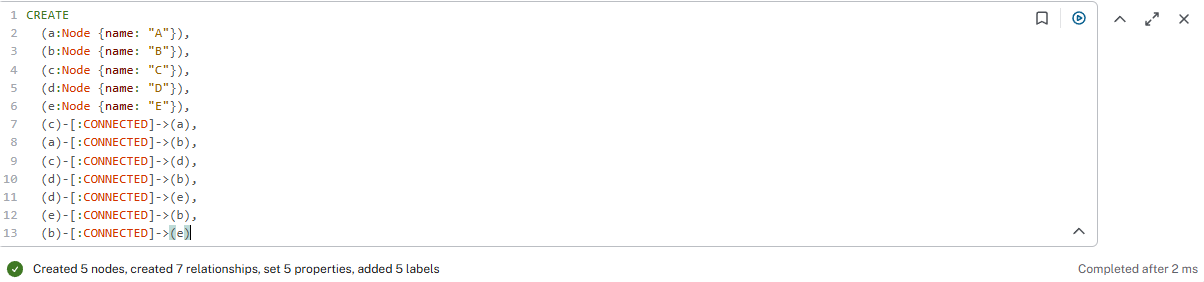
Создать структуру графа (узлы A, B, C, D, E со связями CONNECTED)
cypher
CREATE (a:Node {name: "A"}), (b:Node {name: "B"}), (c:Node {name: "C"}), (d:Node {name: "D"}), (e:Node {name: "E"}), (c)-[:CONNECTED]->(a), (a)-[:CONNECTED]->(b), (c)-[:CONNECTED]->(d), (d)-[:CONNECTED]->(b), (d)-[:CONNECTED]->(e), (e)-[:CONNECTED]->(b), (b)-[:CONNECTED]->(e);
Результат
Результат 2
Результат 3
// Lab 02 · Neo4j
Запросы к графу фильмов (Movies)
Цель: выполнить запросы к графу Movie/Person в Neo4j и оформить результаты.
01
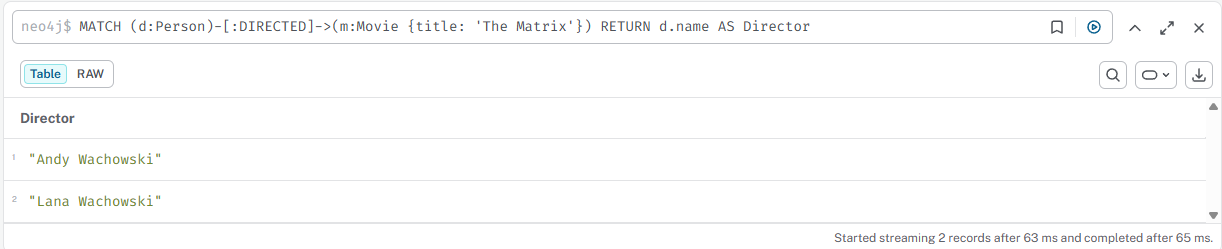
Найти режиссёра фильма "The Matrix"
cypher
MATCH (d:Person)-[:DIRECTED]->(m:Movie {title: 'The Matrix'}) RETURN d.name AS Director
Результат
02
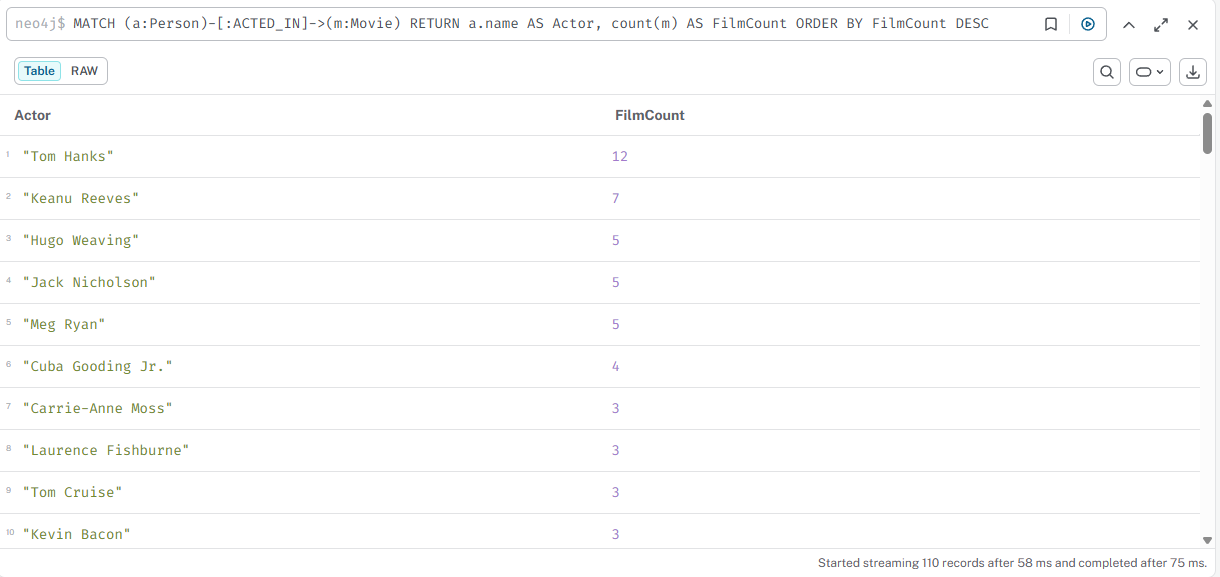
Для каждого актёра вывести количество фильмов
cypher
MATCH (a:Person)-[:ACTED_IN]->(m:Movie) RETURN a.name AS Actor, count(m) AS FilmCount ORDER BY FilmCount DESC
Результат
03
Найти актёра с наибольшим числом фильмов
cypher
MATCH (a:Person)-[:ACTED_IN]->(m:Movie) RETURN a.name AS Actor, count(m) AS FilmCount ORDER BY FilmCount DESC LIMIT 1
Результат

04
Фильм с наибольшим количеством участников (актёры + режиссёры)
cypher
MATCH (m:Movie) OPTIONAL MATCH (p:Person)-[:ACTED_IN|DIRECTED]->(m) RETURN m.title AS Movie, count(DISTINCT p) AS TotalPeople ORDER BY TotalPeople DESC LIMIT 1
Результат

// Lab 03 · Neo4j
Изменение данных в графе
Цель: операции добавления, обновления и удаления данных в Neo4j.
01
Добавить нового пользователя и отзыв на фильм
cypher
MERGE (p:Person {name: "Ravan Mirsultanov"}) ON CREATE SET p.created = timestamp() MERGE (m:Movie {title: "The Matrix"}) CREATE (p)-[:REVIEWED {summary: "Mind-blowing experience, absolute classic!", rating: 95}]->(m)
cypher — проверка
MATCH (p:Person {name: "Ravan Mirsultanov"}) RETURN p
Результат
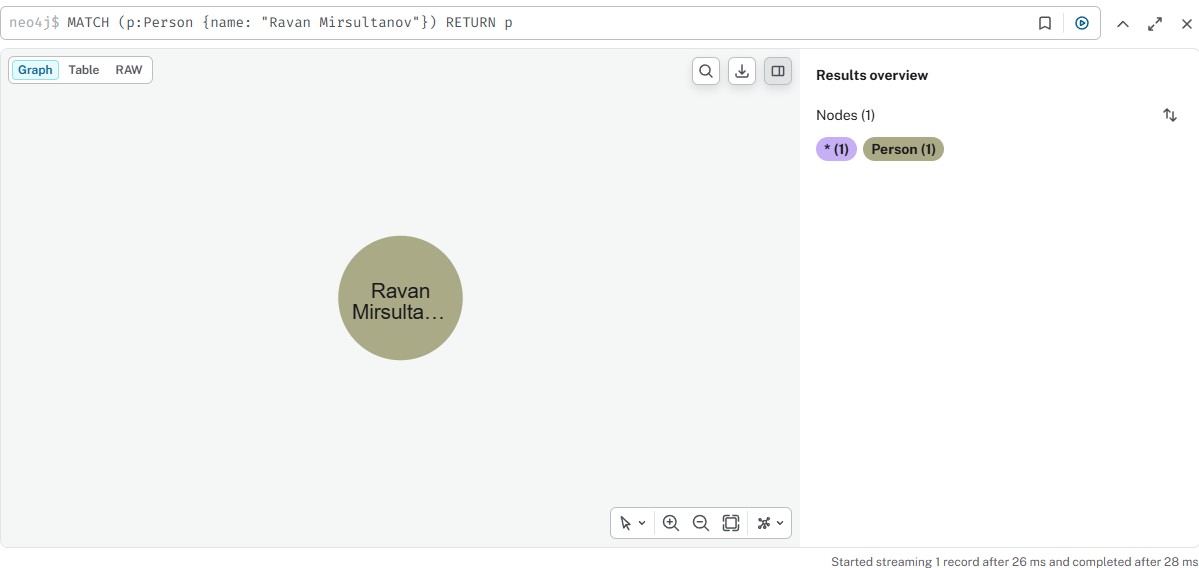
02
Обновить слоган фильма
cypher
MATCH (m:Movie {title: "The Matrix"}) SET m.tagline = "Free your mind." RETURN m.title, m.tagline
Результат

03
Добавить всем фильмам свойство updatedAt
cypher
MATCH (m:Movie) SET m.updatedAt = timestamp() RETURN m.title, m.updatedAt
Результат
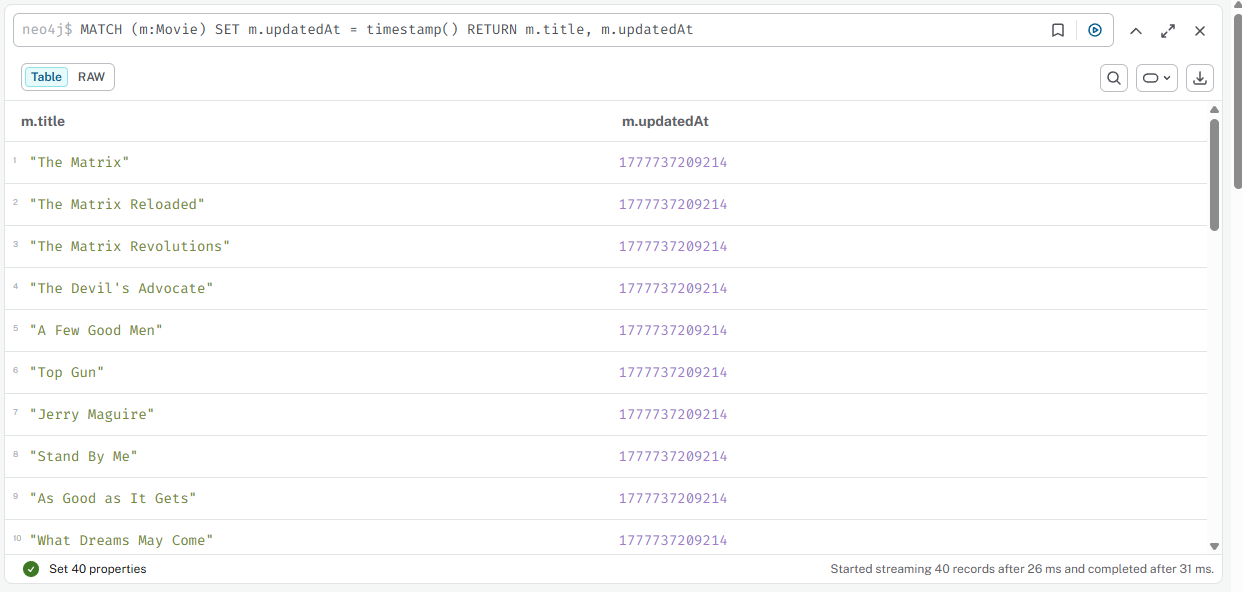
04
Добавить метку Actor всем людям, снимавшимся в фильмах
cypher
MATCH (p:Person)-[:ACTED_IN]->(:Movie) SET p:Actor RETURN p.name ORDER BY p.name
Результат
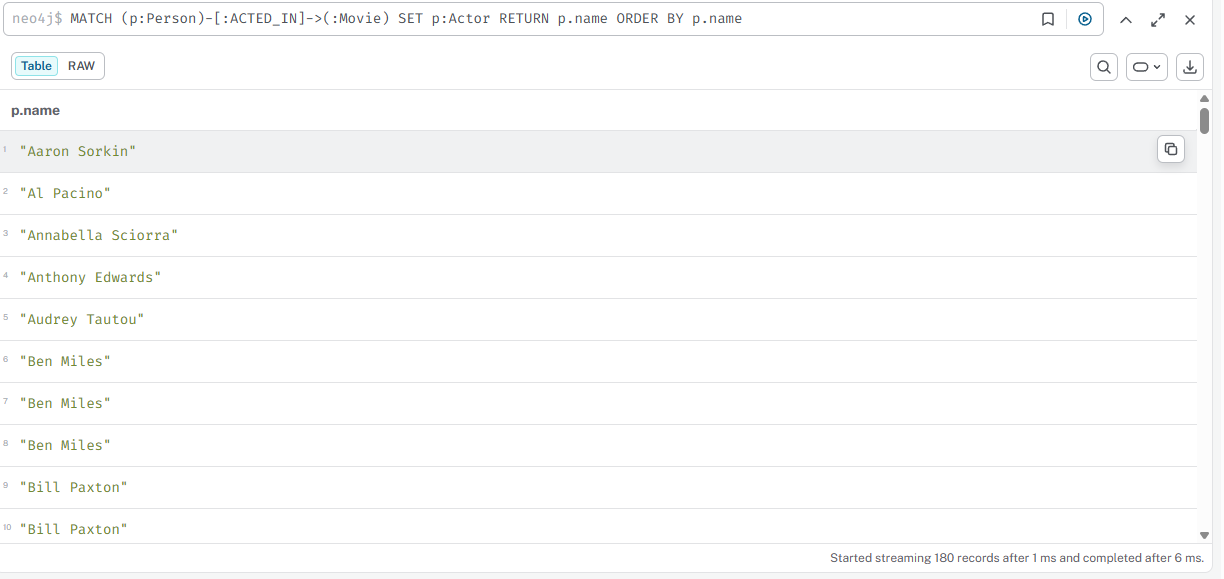
Дополнительная проверка
05
Создать нескольких пользователей через UNWIND
cypher
UNWIND ["Ravan", "Artur", "Misha", "Daniil"] AS userName MERGE (p:Person {name: userName}) ON CREATE SET p.created = timestamp() RETURN p.name
Результат
06
Создать связь FOLLOWS между всеми, кто писал отзывы
cypher
MATCH (p1:Person)-[:REVIEWED]->(:Movie) MATCH (p2:Person)-[:REVIEWED]->(:Movie) WHERE p1 <> p2 MERGE (p1)-[:FOLLOWS]->(p2) RETURN p1.name, p2.name
Результат
07
Удалить пользователей, созданных сегодня
cypher
MATCH (p:Person) WHERE p.created >= (timestamp() - 86400000) DETACH DELETE p
cypher — проверка
MATCH (p:Person) WHERE p.created >= (timestamp() - 86400000) RETURN p.name
Результат

Дополнительная проверка

// Lab 04 · Neo4j
Сложные Cypher-запросы
Цель: закрепить навыки написания Cypher-запросов: агрегации, метки, связи, пути.
01
Все фильмы конкретного актёра (Tom Hanks)
cypher
MATCH (p:Person {name: 'Tom Hanks'})-[:ACTED_IN]->(m:Movie) RETURN m.title
Результат
02
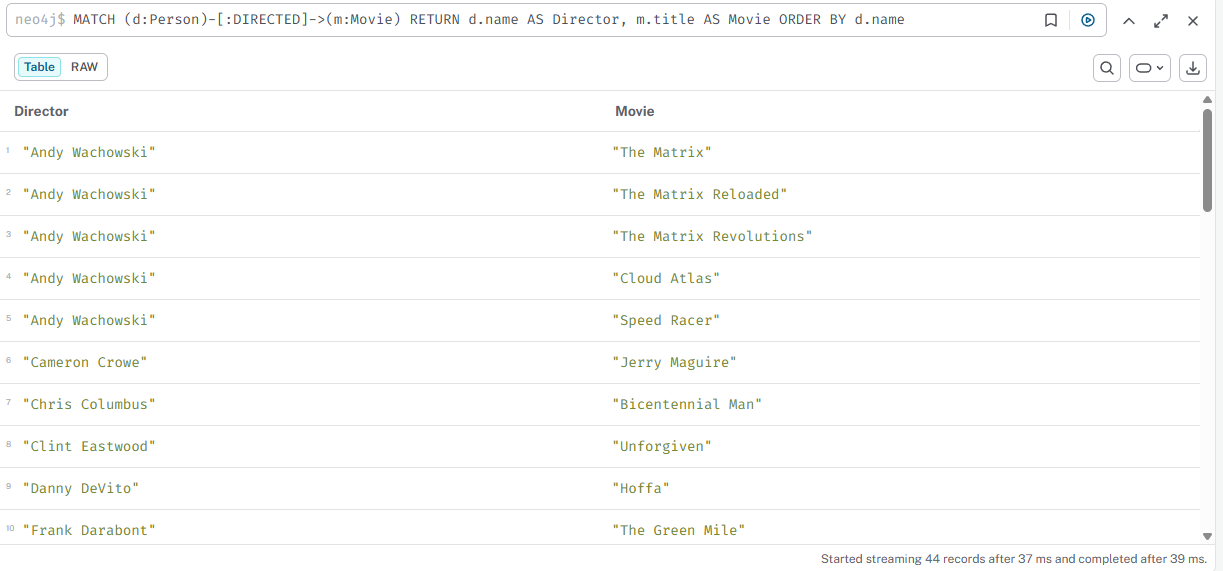
Все режиссёры и их фильмы
cypher
MATCH (d:Person)-[:DIRECTED]->(m:Movie) RETURN d.name AS Director, m.title AS Movie ORDER BY d.name
Результат
03
Пары актёров из одного фильма
cypher
MATCH (a1:Person)-[:ACTED_IN]->(m:Movie)<-[:ACTED_IN]-(a2:Person) WHERE a1.name < a2.name RETURN a1.name AS Actor1, a2.name AS Actor2, m.title AS Movie ORDER BY Movie
Результат
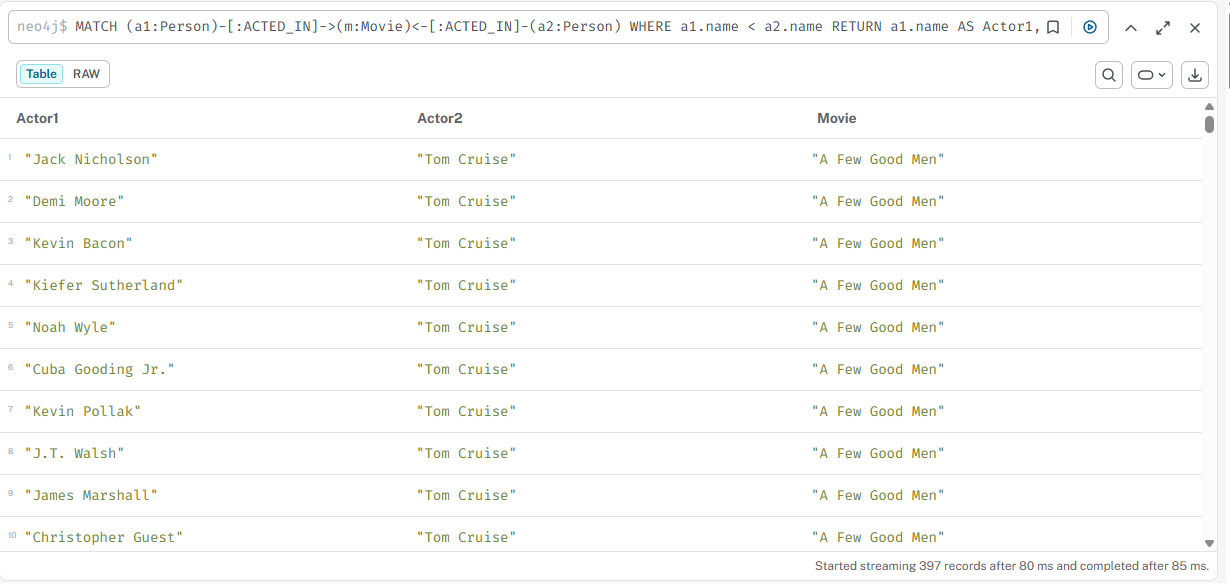
04
Количество фильмов для каждого актёра
cypher
MATCH (p:Person)-[:ACTED_IN]->(m:Movie) RETURN p.name AS Actor, count(m) AS Films ORDER BY Films DESC
Результат
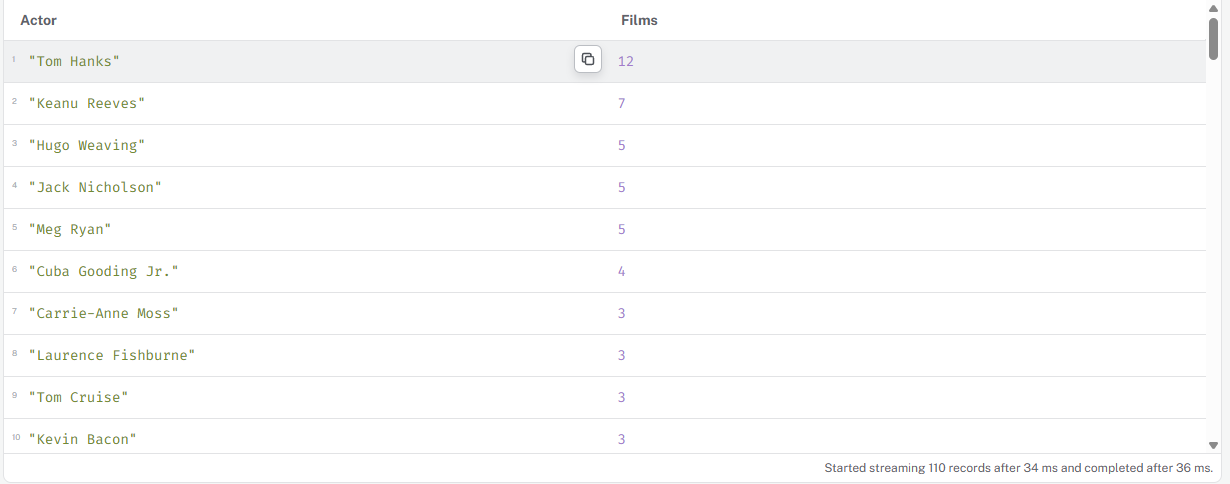
05
Актёры, снявшиеся более чем в 3 фильмах
cypher
MATCH (p:Person)-[:ACTED_IN]->(m:Movie) WITH p, count(m) AS total WHERE total > 3 RETURN p.name AS Actor, total AS Films ORDER BY Films DESC
Результат
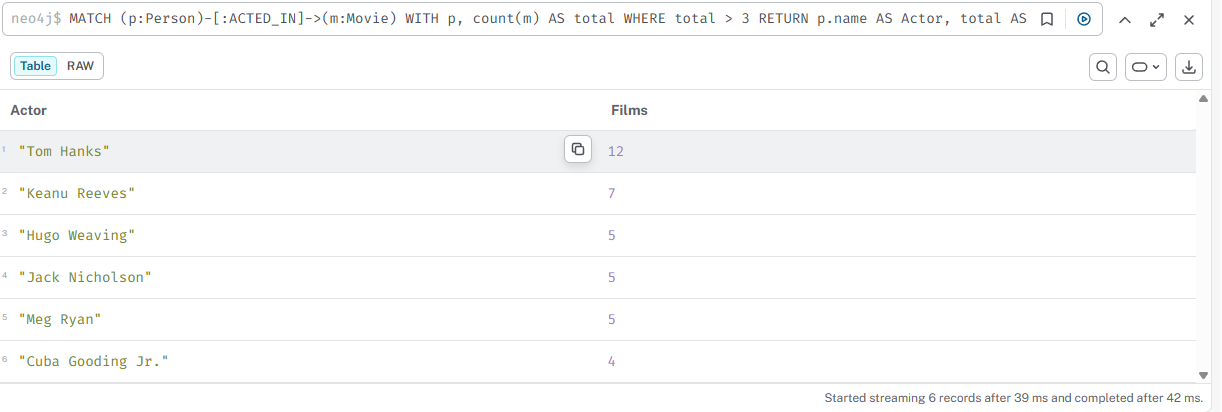
06
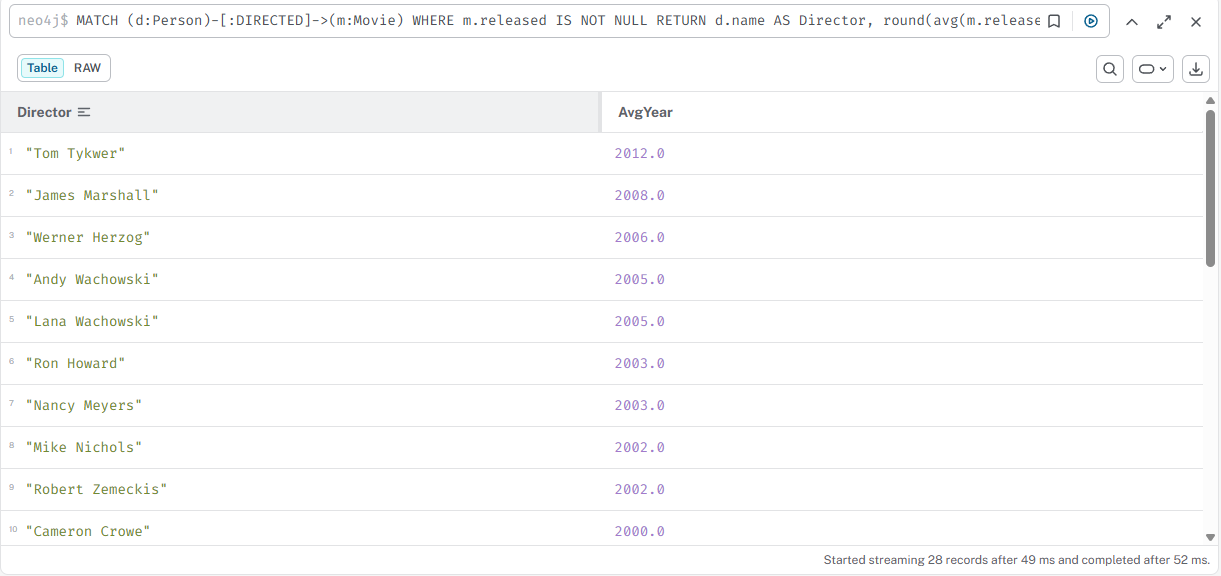
Средний год выпуска фильмов каждого режиссёра
cypher
MATCH (d:Person)-[:DIRECTED]->(m:Movie) WHERE m.released IS NOT NULL RETURN d.name AS Director, round(avg(m.released)) AS AvgYear ORDER BY AvgYear DESC
Результат
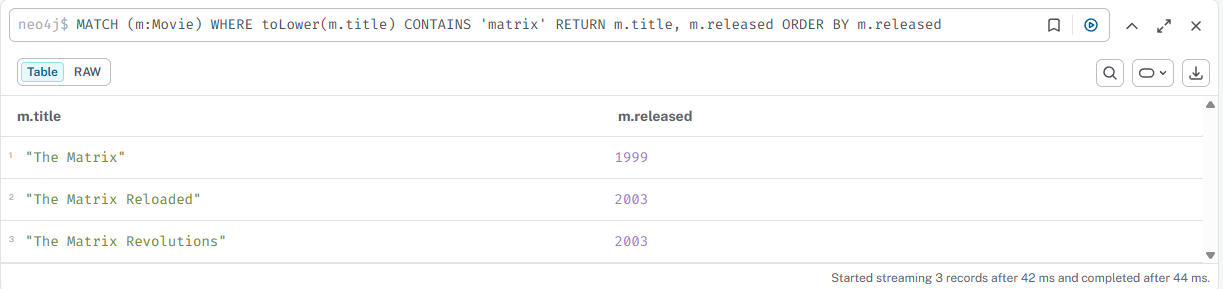
07
Поиск фильмов по части названия (CONTAINS 'matrix')
cypher
MATCH (m:Movie) WHERE toLower(m.title) CONTAINS 'matrix' RETURN m.title, m.released ORDER BY m.released
Результат
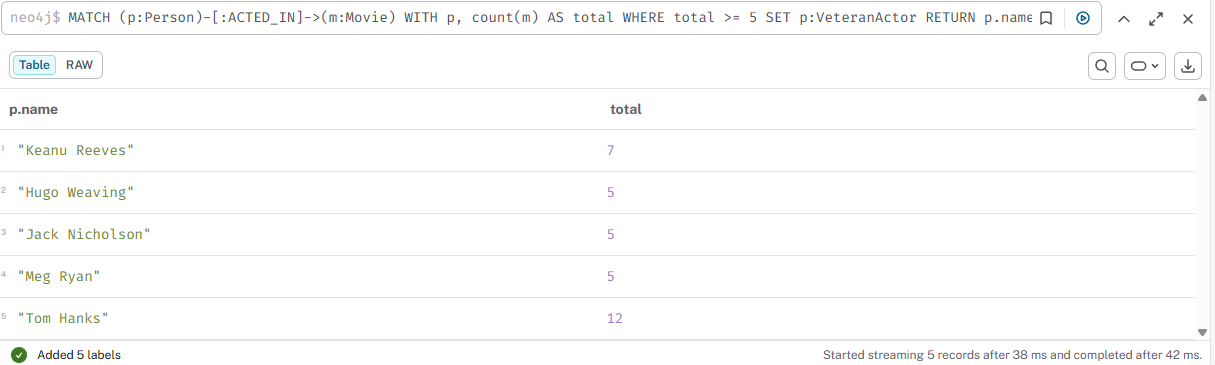
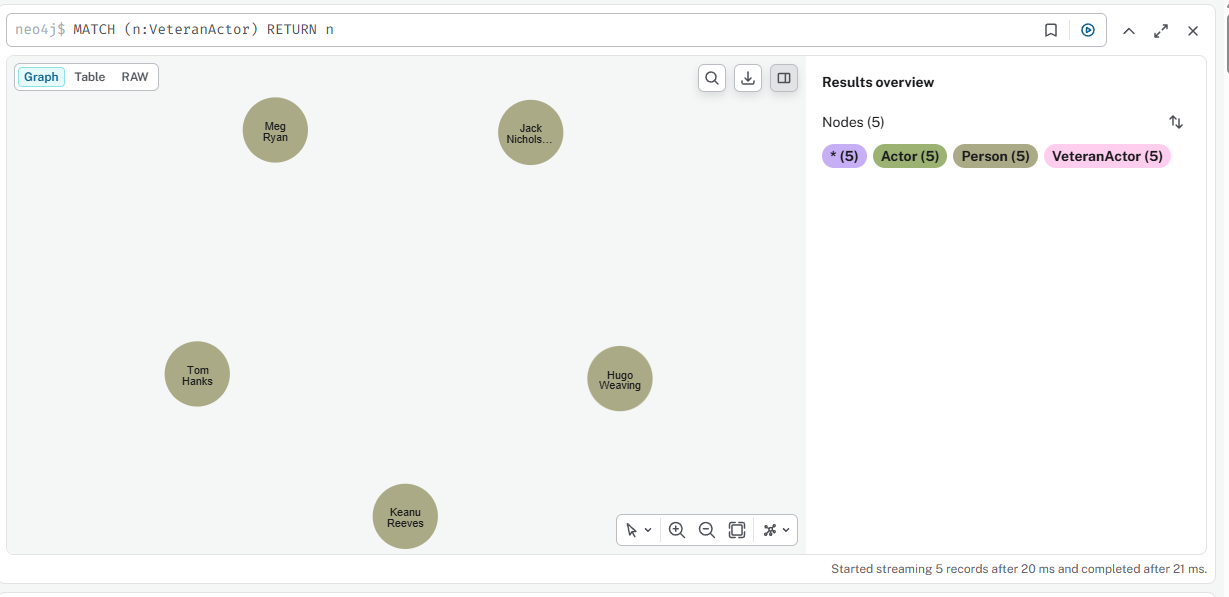
08
Добавить метку VeteranActor актёрам с 5+ фильмами
cypher
MATCH (p:Person)-[:ACTED_IN]->(m:Movie) WITH p, count(m) AS total WHERE total >= 5 SET p:VeteranActor RETURN p.name, total
Результат
Результат 2
09
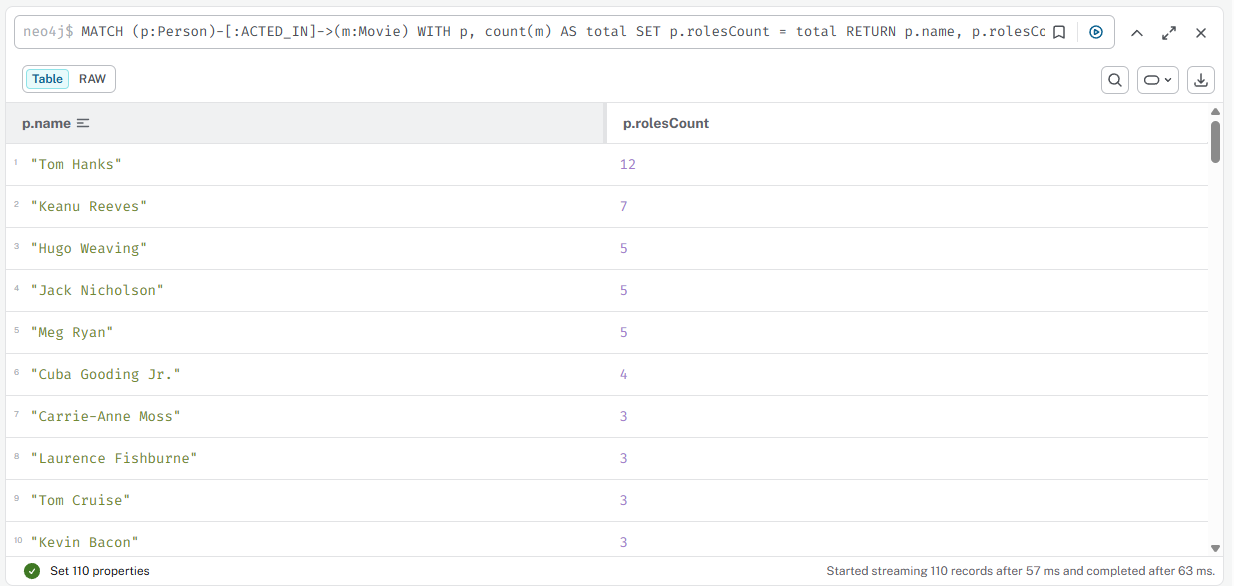
Добавить свойство rolesCount актёрам
cypher
MATCH (p:Person)-[:ACTED_IN]->(m:Movie) WITH p, count(m) AS total SET p.rolesCount = total RETURN p.name, p.rolesCount ORDER BY p.rolesCount DESC
Результат
10
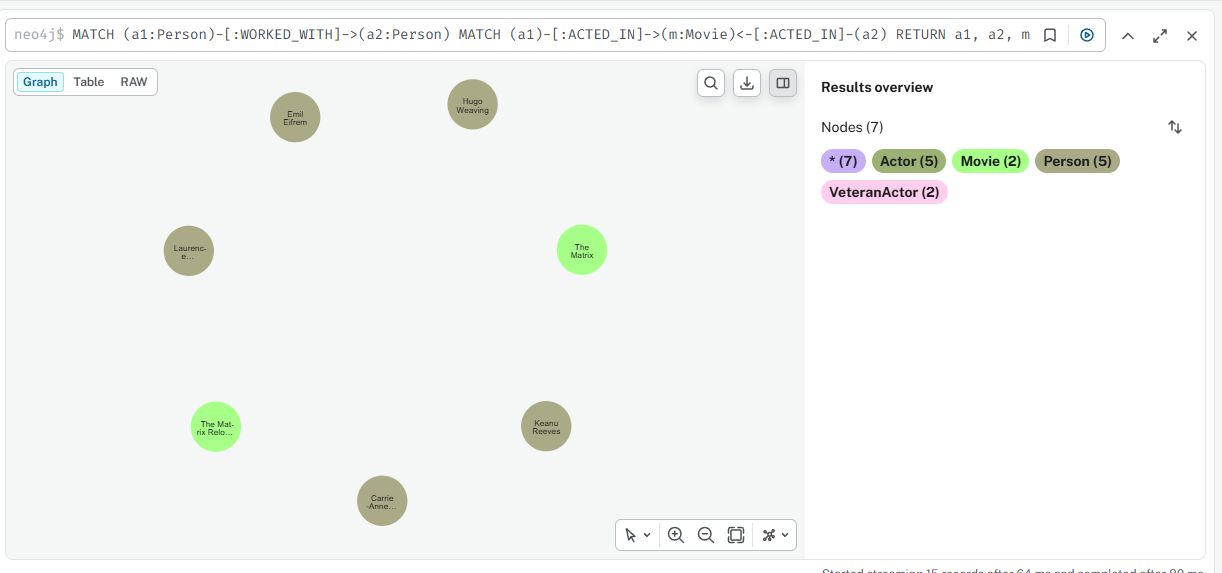
Создать связь WORKED_WITH между актёрами одного фильма
cypher
MATCH (a1:Person)-[:ACTED_IN]->(m:Movie)<-[:ACTED_IN]-(a2:Person) WHERE a1.name < a2.name MERGE (a1)-[:WORKED_WITH]->(a2)
cypher — визуализация
MATCH (a1:Person)-[:WORKED_WITH]->(a2:Person) RETURN a1, a2 LIMIT 25
Результат

Результат 2
11
Добавить свойство "delete" фильмам без даты выпуска
cypher
MATCH (m:Movie) WHERE m.released IS NULL SET m.delete = true RETURN m.title
12
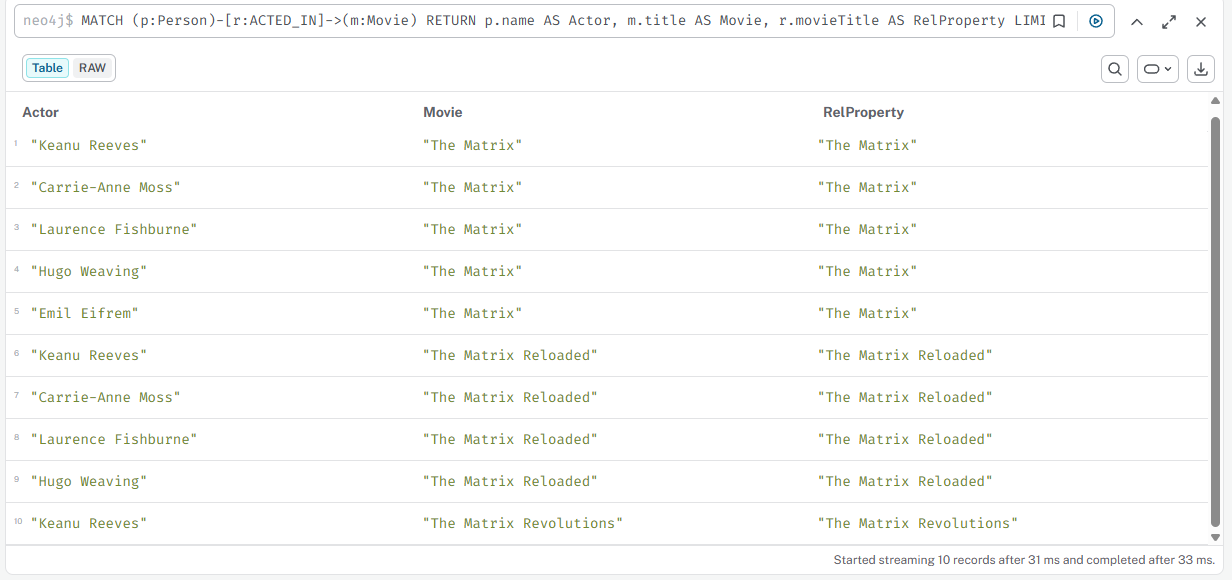
FOREACH — проставить свойство на связях актёров
cypher
MATCH (m:Movie)<-[r:ACTED_IN]-(p:Person) WITH m, collect(r) AS rels FOREACH (rel IN rels | SET rel.movieTitle = m.title)
Результат
13
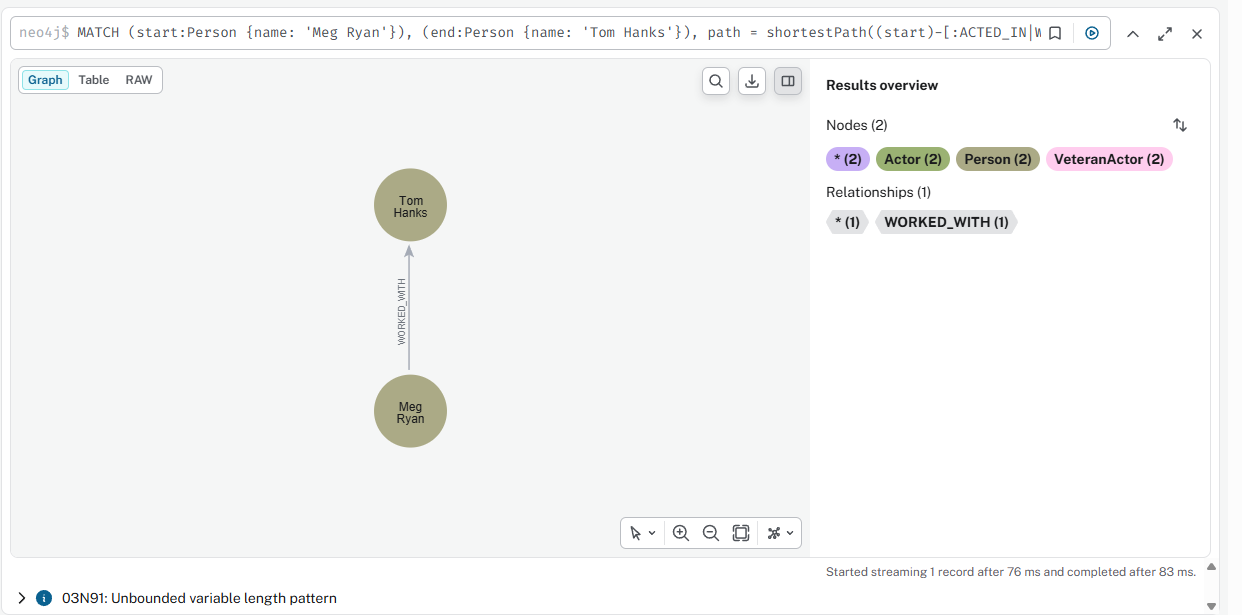
Кратчайший путь между Мег Райан и Томом Хэнксом
cypher
MATCH (start:Person {name: 'Meg Ryan'}), (end:Person {name: 'Tom Hanks'}), path = shortestPath((start)-[:ACTED_IN|WORKED_WITH*]-(end)) RETURN path, length(path)
Результат
14
Создать 5 новых фильмов через UNWIND
cypher
UNWIND [ {title: 'Dune', released: 2021, tagline: 'Beyond fear, destiny awaits'}, {title: 'Parasite', released: 2019, tagline: 'Act like you own the place'}, {title: 'The Lighthouse', released: 2019, tagline: 'How long have we been on this rock?'}, {title: 'Arrival', released: 2016, tagline: 'Why are they here?'}, {title: 'Blade Runner 2049', released: 2017, tagline: 'The key to the future is finally unearthed'} ] AS data CREATE (m:Movie {title: data.title, released: data.released, tagline: data.tagline}) RETURN m.title, m.released
Результат
// Lab 05 · MongoDB (часть 1)
Базовые запросы MongoDB
Цель: освоить базовые операции find, sort, countDocuments, updateMany в MongoDB.
01
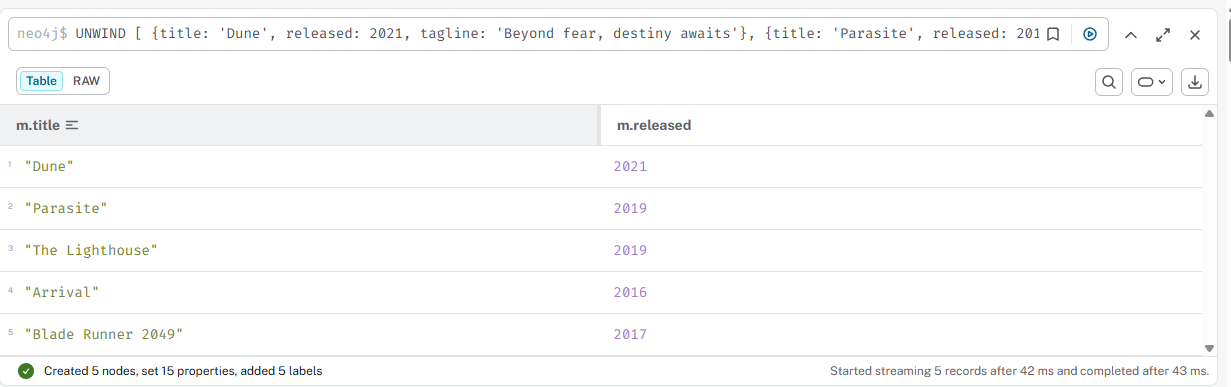
Найти авторов из России
javascript
db.authors.find({ country: "Россия" })
Результат
02
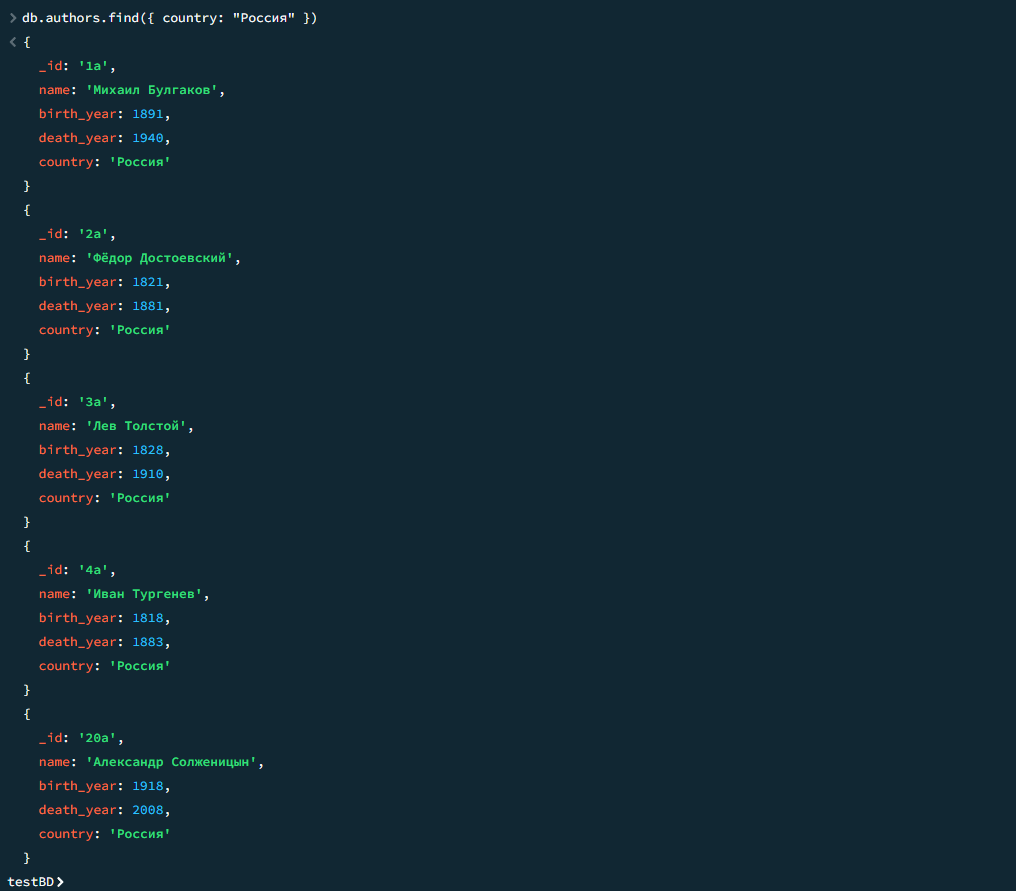
Книги, изданные после 1956 года
javascript
db.books.find({ year: { $gt: 1956 } })
Результат
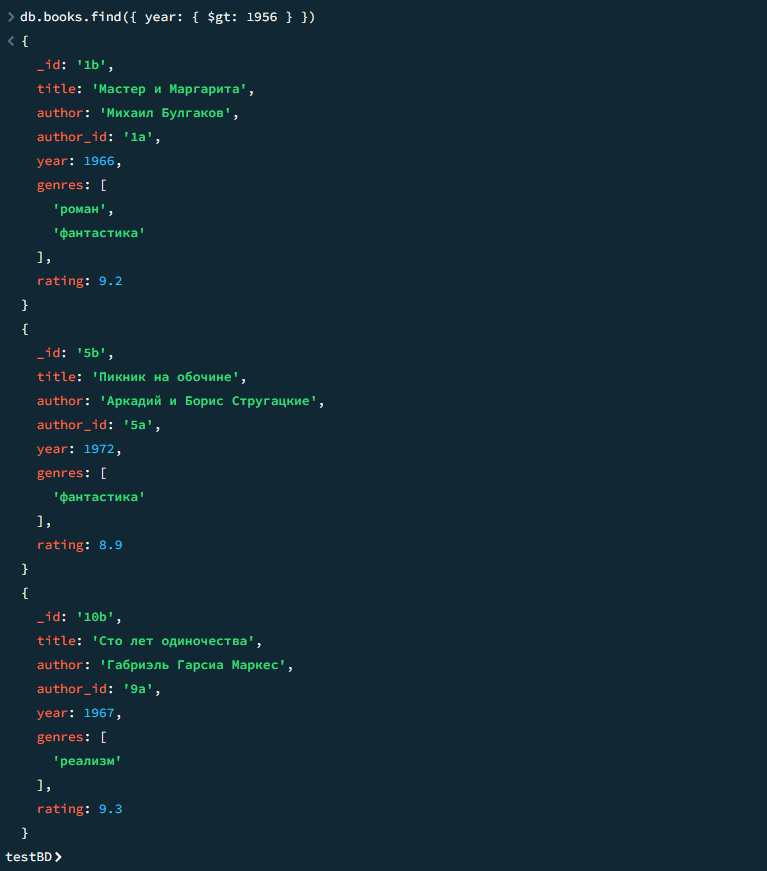
03
Книги с рейтингом выше 8.5
javascript
db.books.find({ rating: { $gt: 8.5 } }).sort({ rating: -1 })
Результат
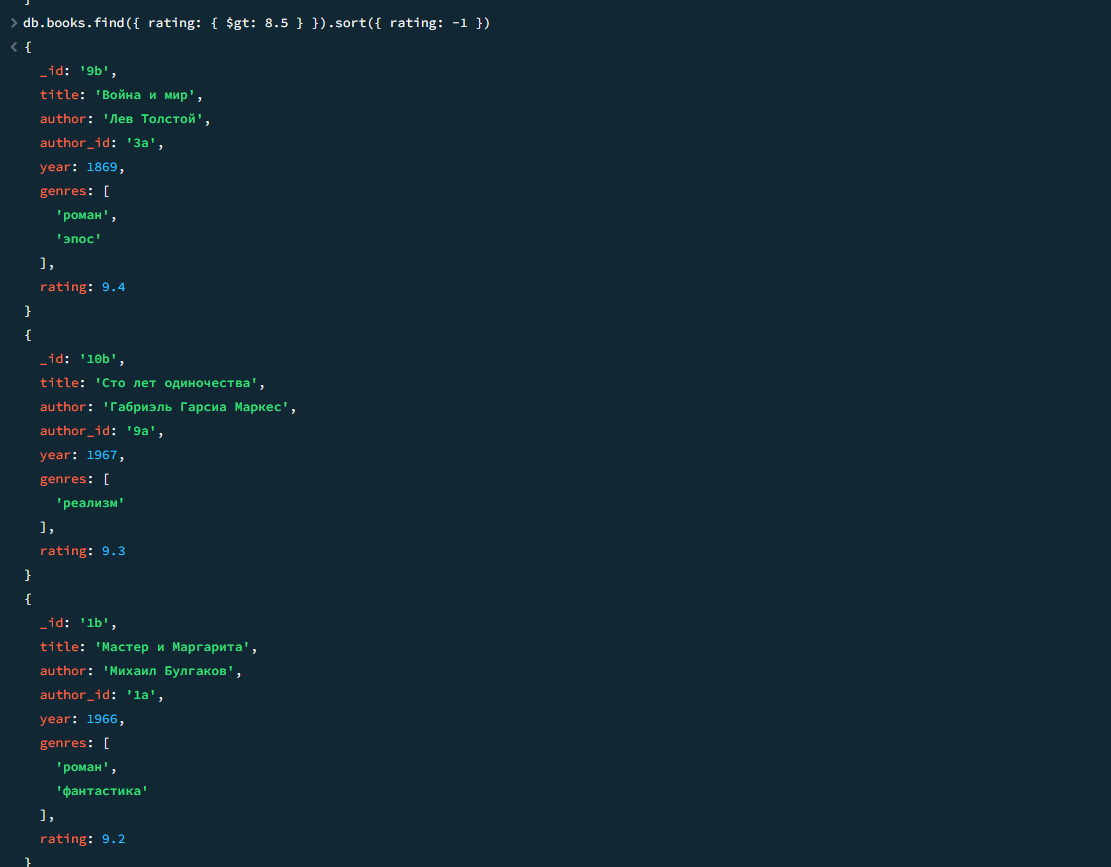
Результат 2
Результат 3
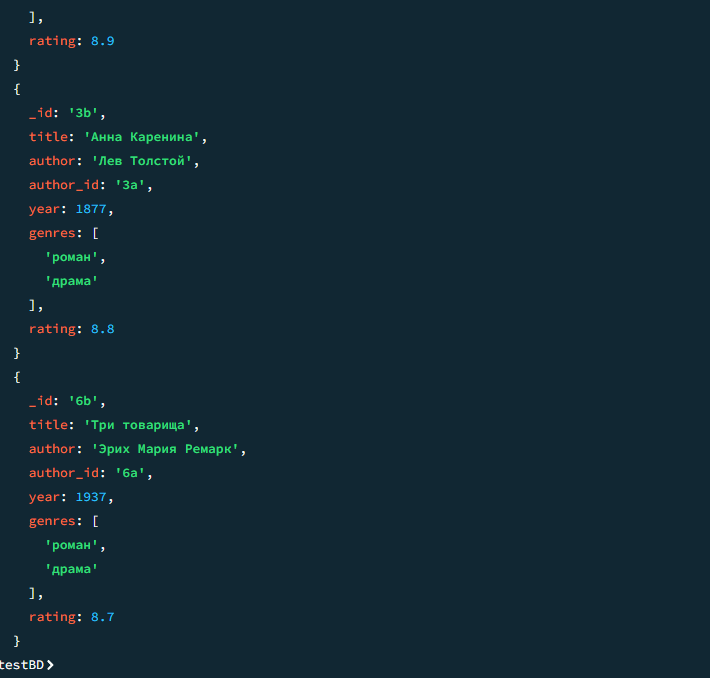
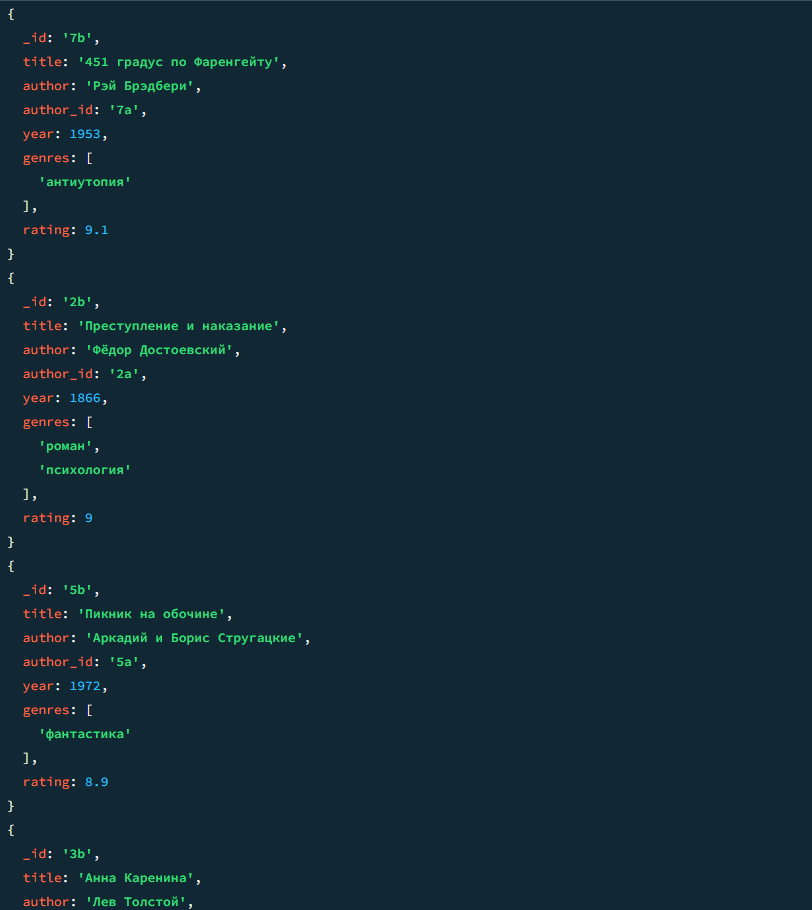
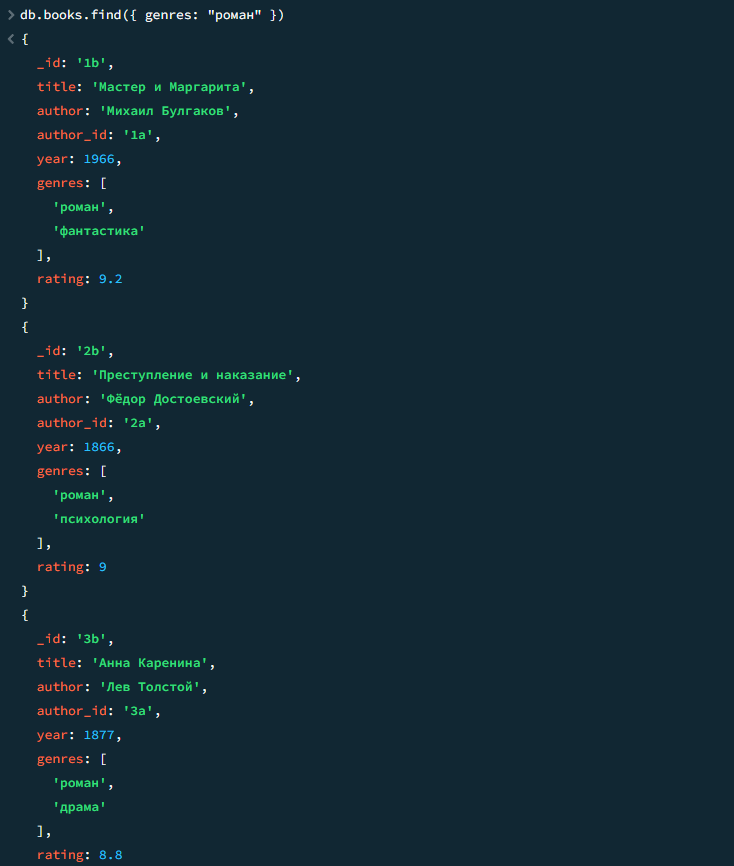
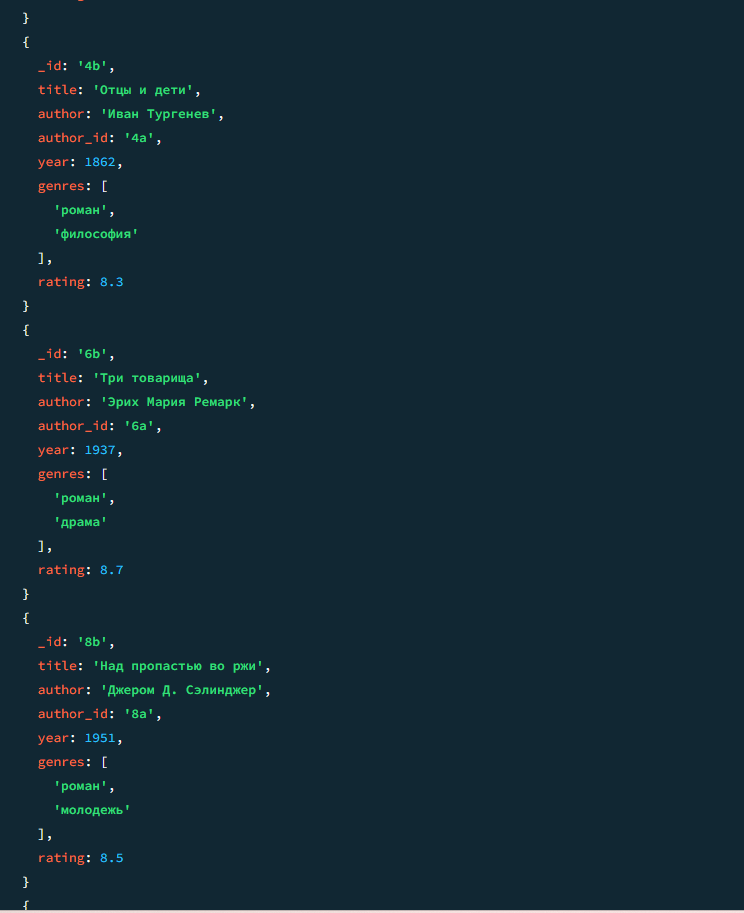
04
Книги жанра "роман"
javascript
db.books.find({ genres: "роман" })
Результат
Результат 2
Результат 3
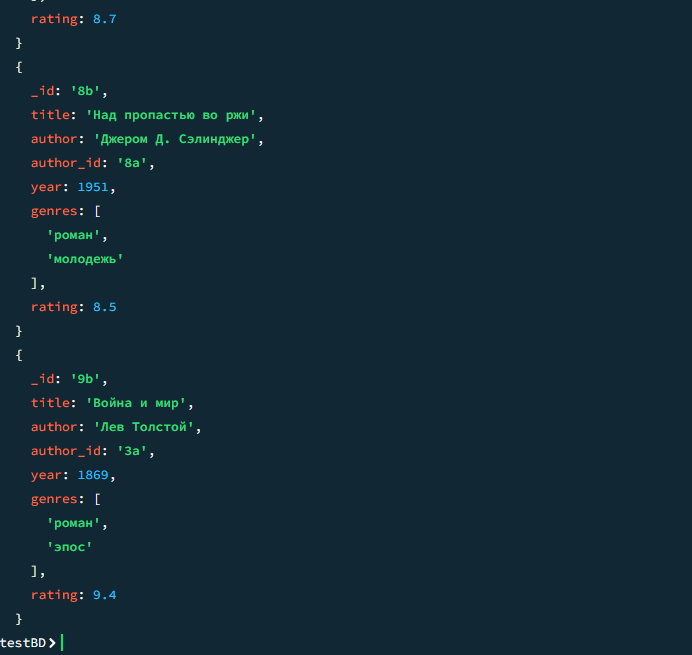
05
Книги автора «Лев Толстой»
javascript
db.books.find({ author: "Лев Толстой" })
Результат
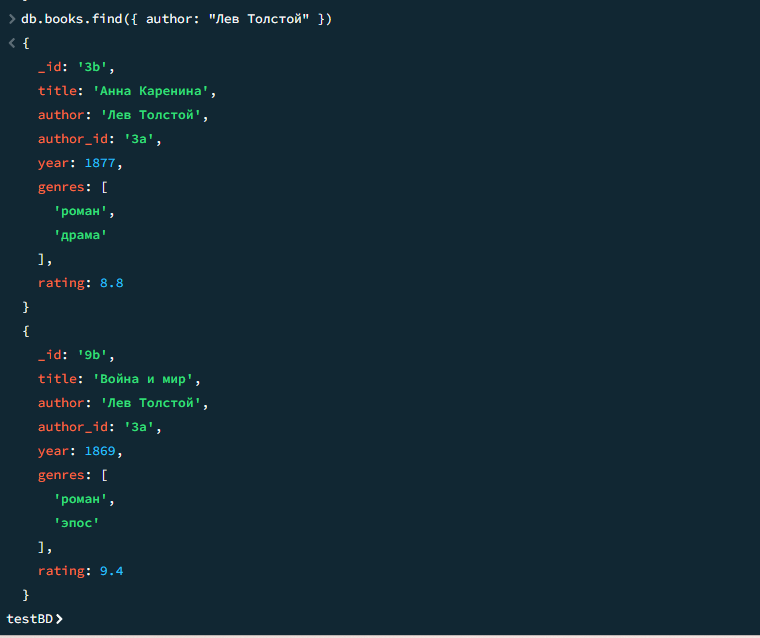
06
Выводить только название и автора книги
javascript
db.books.find({}, { title: 1, author: 1, _id: 0 })
Результат
Результат 2
07
Только имена пользователей и города
javascript
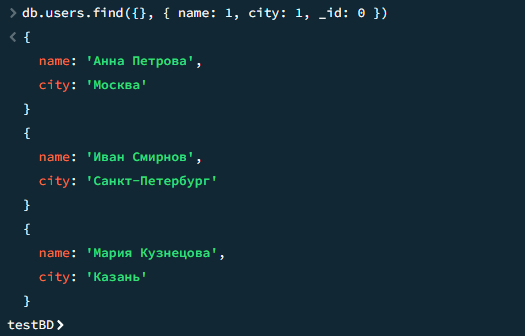
db.users.find({}, { name: 1, city: 1, _id: 0 })
Результат
08
Книги по рейтингу (от лучшего к худшему)
javascript
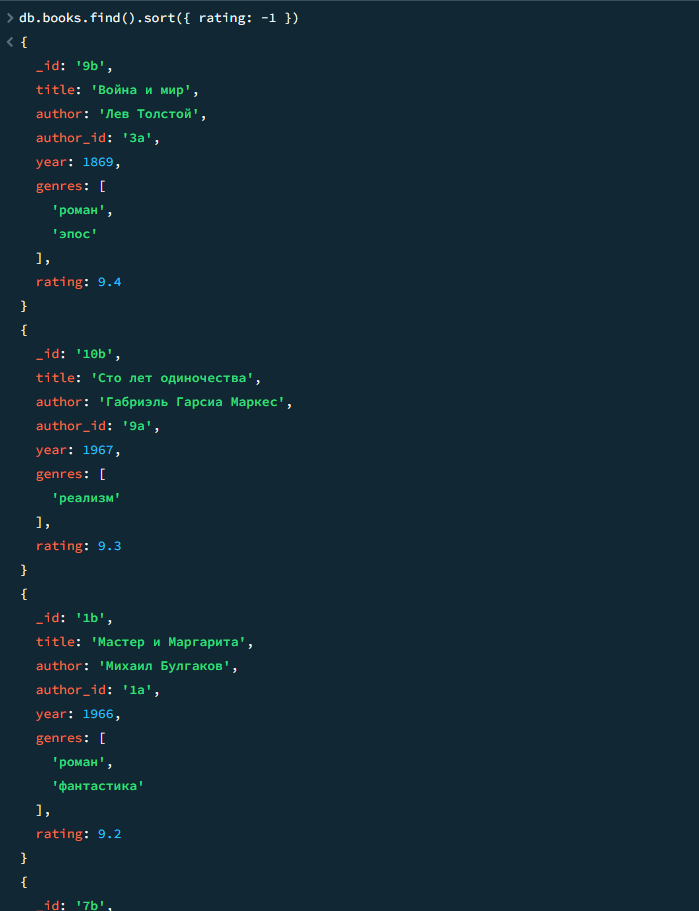
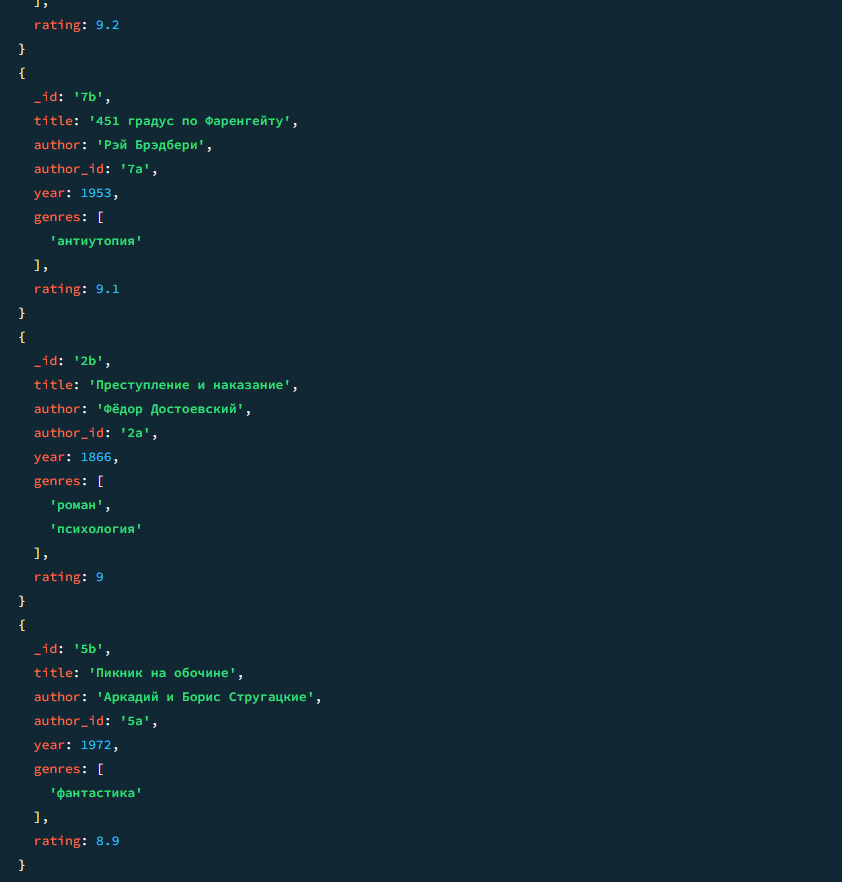
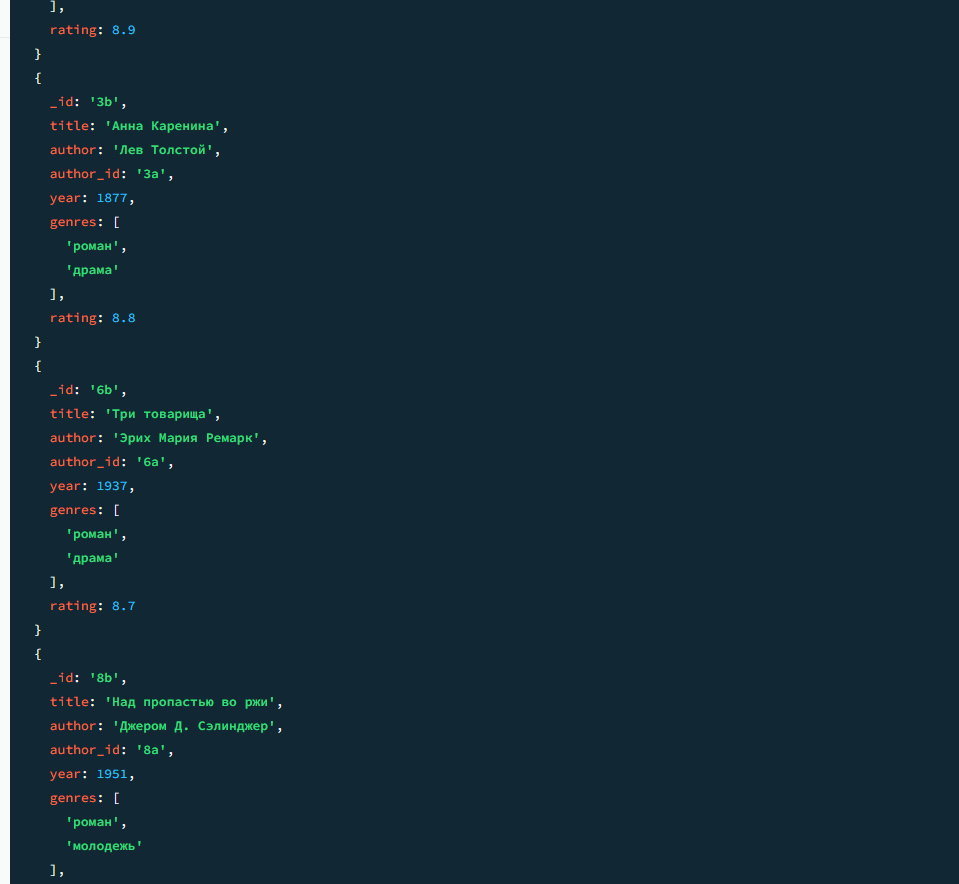
db.books.find().sort({ rating: -1 })
Результат
Результат 2
Результат 3
Результат 4
09
Пользователи по возрасту (от младшего)
javascript
db.users.find().sort({ age: 1 })
Результат
10
Сколько всего книг в базе
javascript
db.books.countDocuments()
Результат
11
Сколько уникальных авторов
javascript
db.books.distinct("author").length
Результат

12
Сколько пользователей из Казани
javascript
db.users.countDocuments({ city: "Казань" })
Результат

13
Пользователи, бравшие хотя бы одну книгу
javascript
db.users.find({ "borrowed_books.0": { $exists: true } })
Результат
14
Пользователи, бравшие книгу с ID = 3b
javascript
db.users.find({ "borrowed_books.book_id": "3b" })
Результат
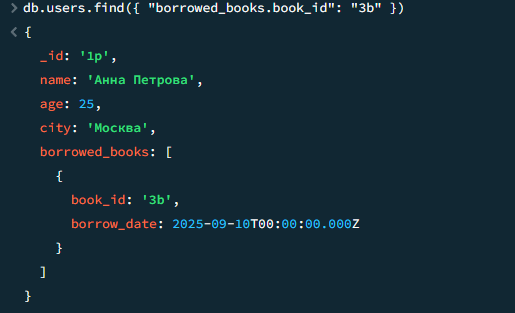
15
Пользователи, бравшие более 2 книг
javascript
db.users.find({ $expr: { $gt: [{ $size: "$borrowed_books" }, 2] } })
Результат
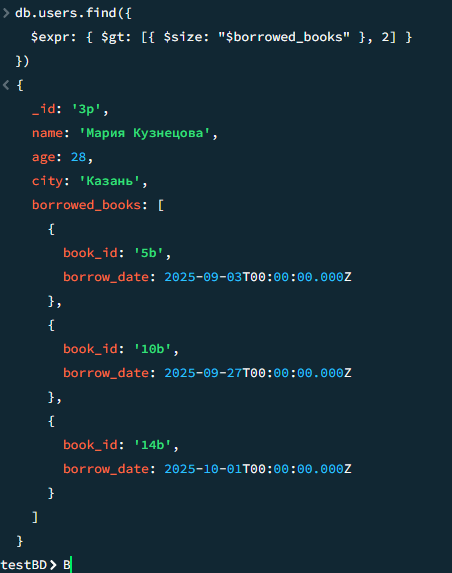
16
Добавить всем пользователям поле membership: "standard"
javascript
db.users.updateMany( {}, { $set: { membership: "standard" } } )
Результат
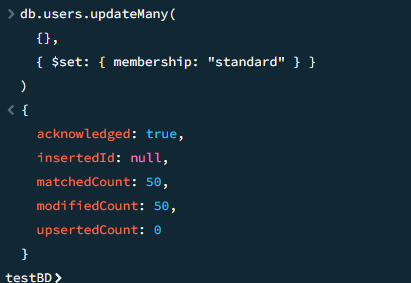
17
Книги с рейтингом > 9 — пометить как рекомендованные
javascript
db.books.updateMany( { rating: { $gt: 9 } }, { $set: { recommended: true } } )
Результат
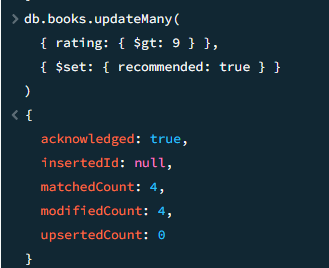
18
Подсчитать сколько книг у каждого автора
javascript
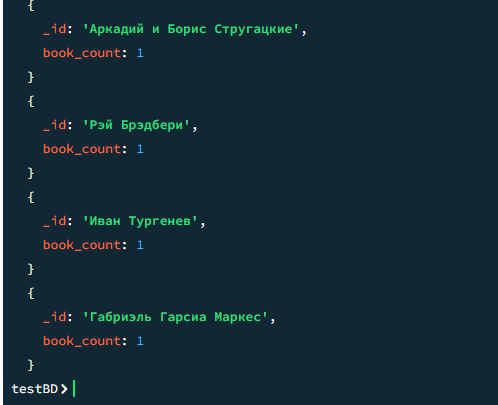
db.books.aggregate([ { $group: { _id: "$author", book_count: { $sum: 1 } }}, { $sort: { book_count: -1 } } ])
Результат
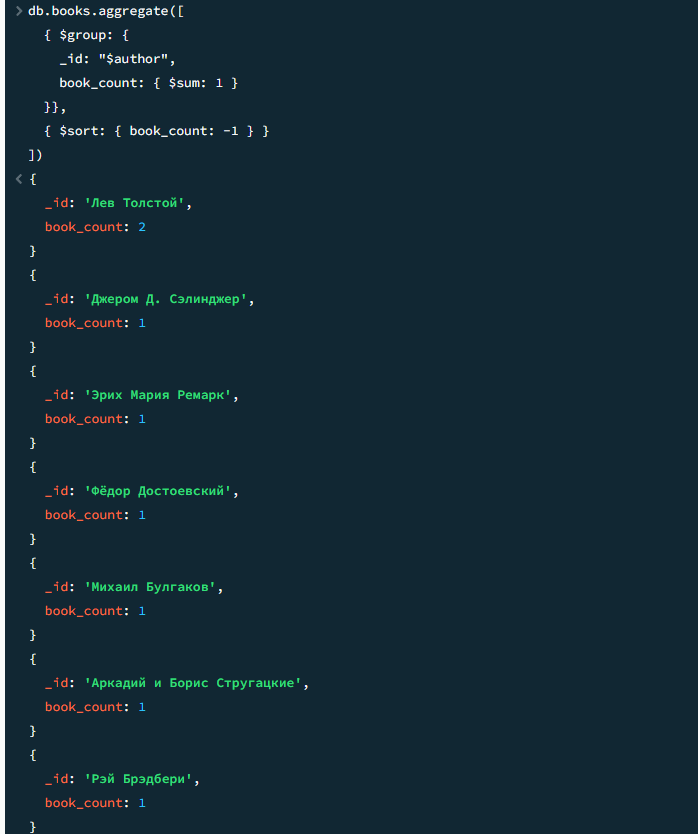
Результат 2
19
Средний рейтинг по авторам
javascript
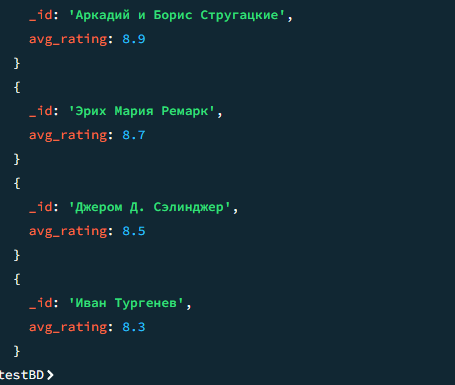
db.books.aggregate([ { $group: { _id: "$author", avg_rating: { $avg: "$rating" } }}, { $sort: { avg_rating: -1 } } ])
Результат
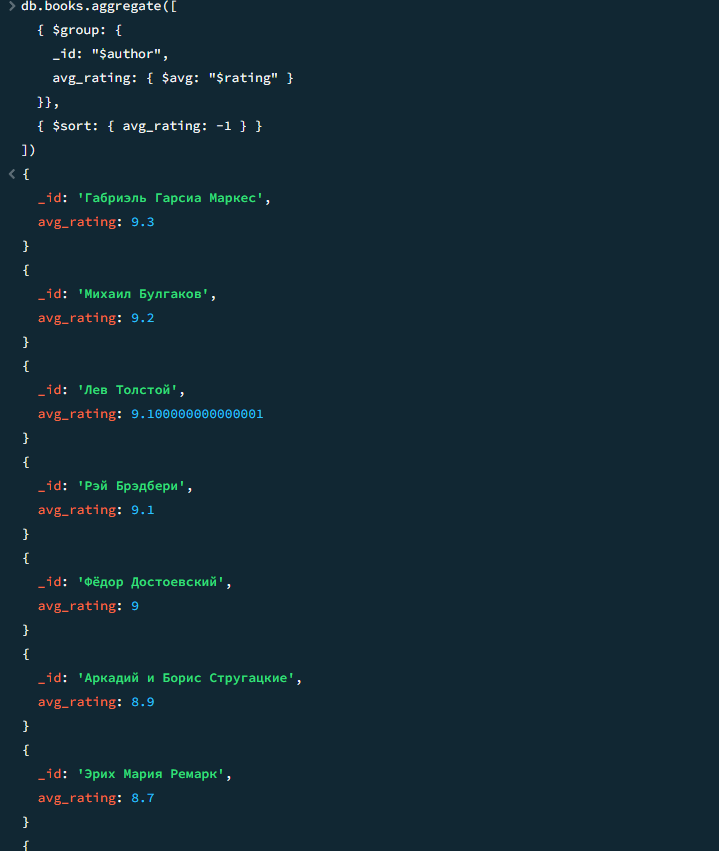
Результат 2
20
Читатели, которые ничего не брали
javascript
db.users.find({ borrowed_books: { $size: 0 } })
Результат
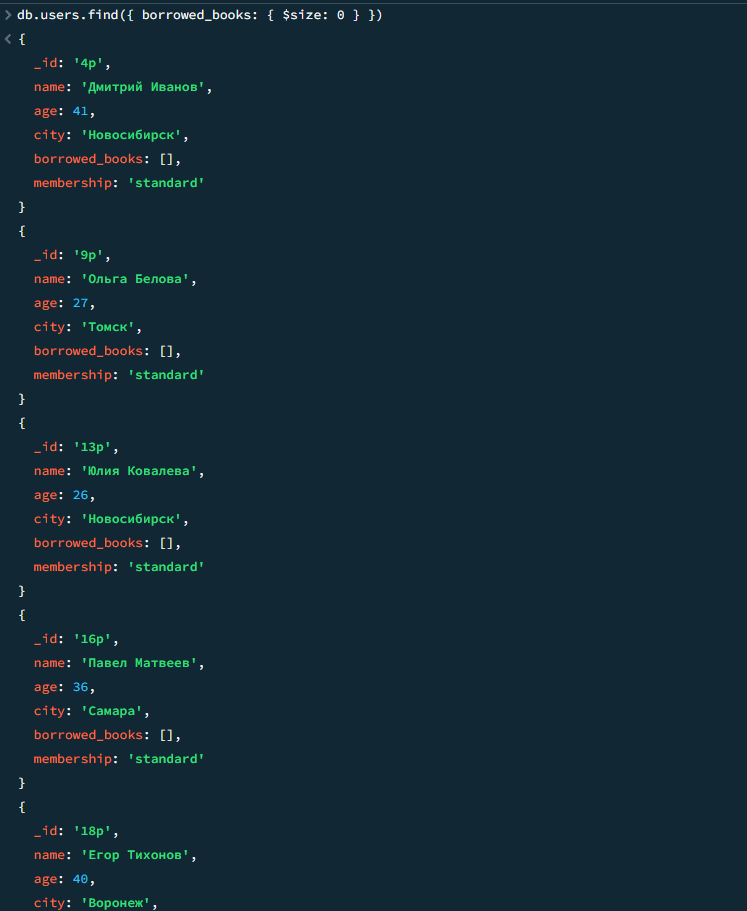
Результат 2
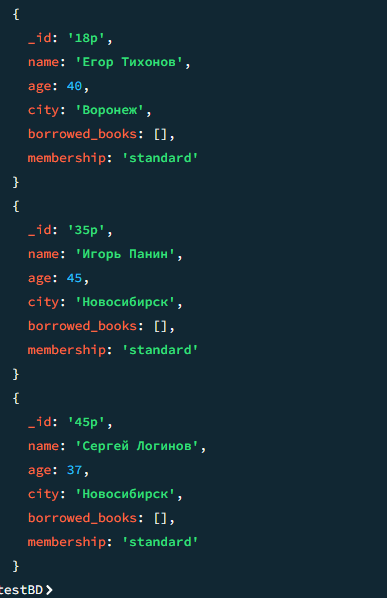
21
Все, кто брал книгу после 15 сентября
javascript
db.users.find({ "borrowed_books.borrow_date": { $gt: ISODate("2025-09-15T00:00:00Z") } })
Результат
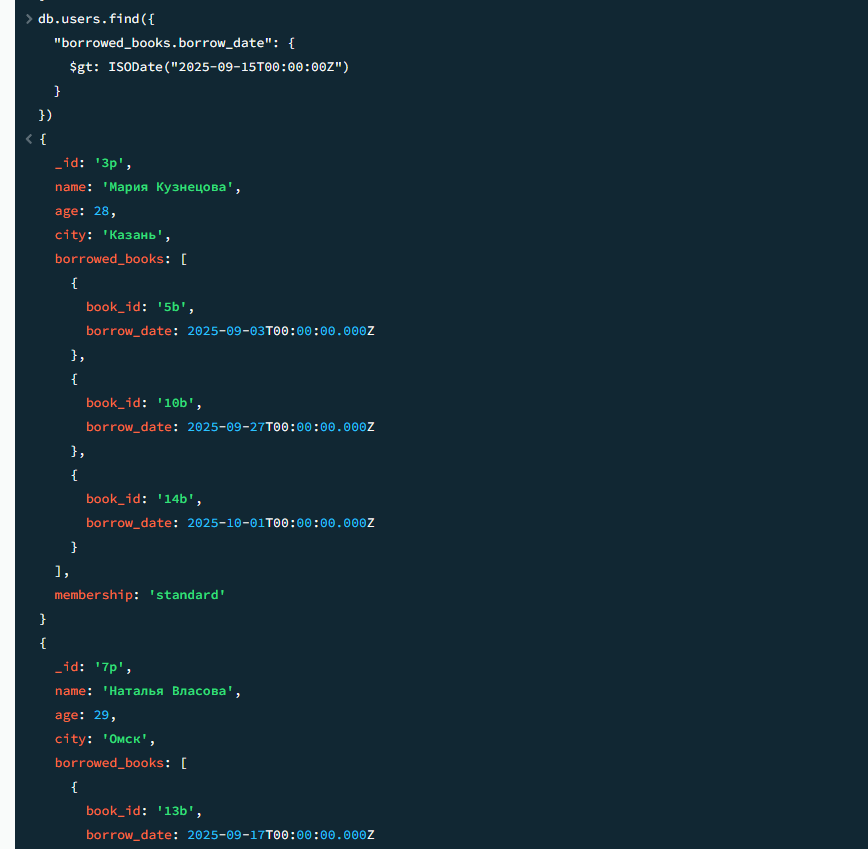
Результат 2
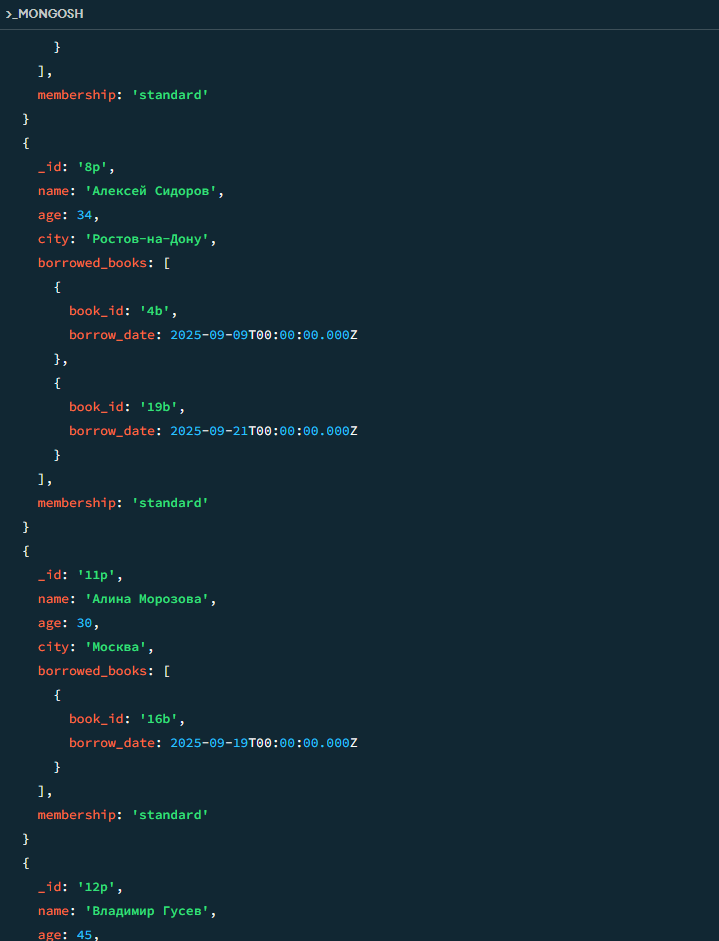
Результат 3
Результат 4
Результат 5
22
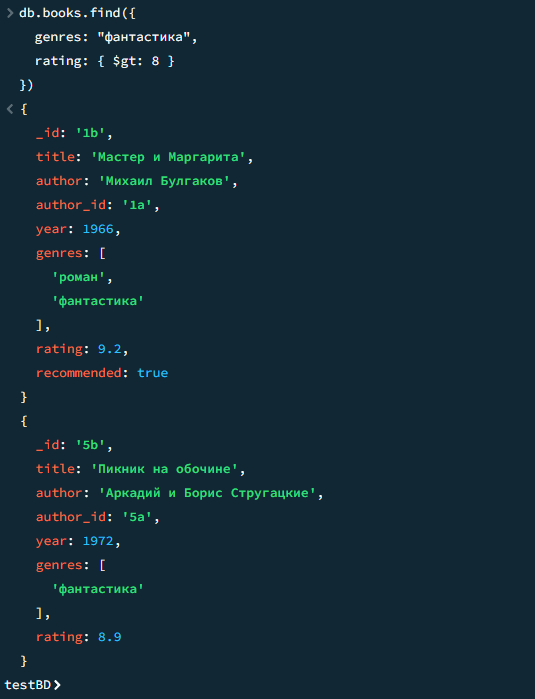
Книги жанра «фантастика» с рейтингом > 8
javascript
db.books.find({ genres: "фантастика", rating: { $gt: 8 } })
Результат
23
Пользователи из Санкт-Петербурга старше 25 лет
javascript
db.users.find({ city: "Санкт-Петербург", age: { $gt: 25 } })
Результат
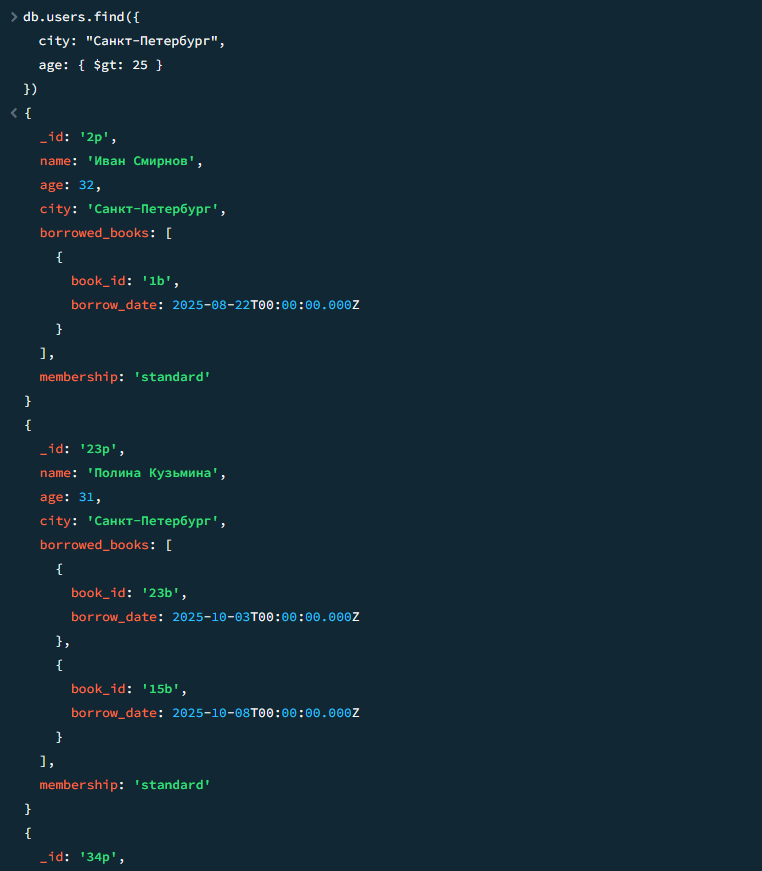
Результат 2
// Lab 05 · MongoDB (часть 2)
Агрегации и сложные запросы
Цель: освоить aggregate pipeline: $group, $lookup, $unwind, $match, $sort, $limit.
01
Количество авторов из каждой страны
javascript
db.authors.aggregate([ { $group: { _id: "$country", count: { $sum: 1 } }}, { $sort: { count: -1 } } ])
Результат
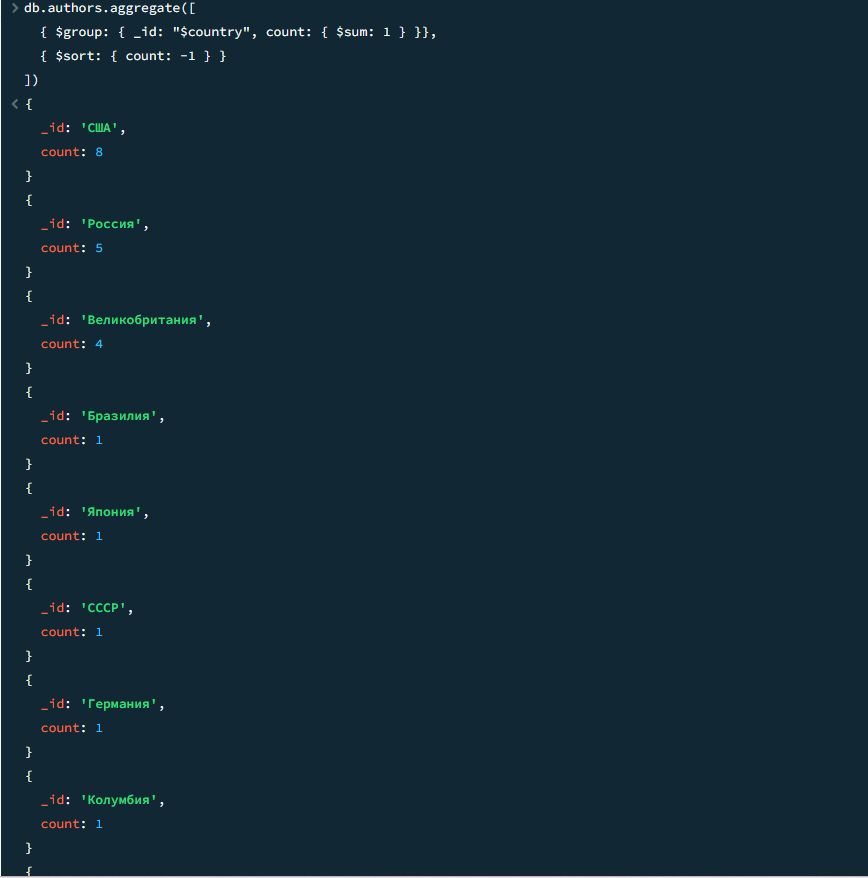
Результат 2
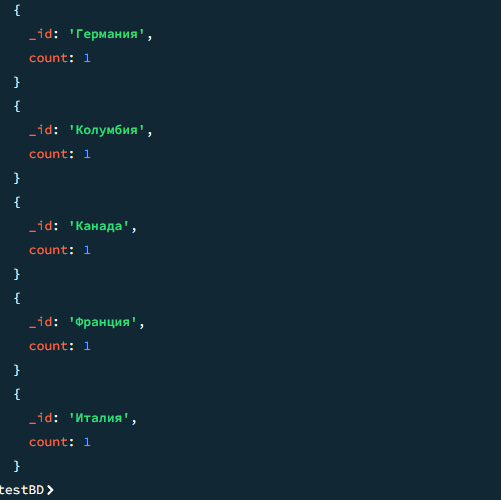
02
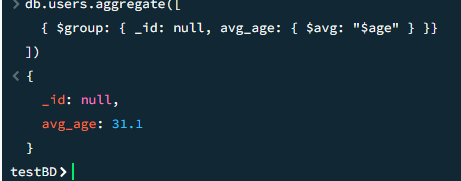
Средний возраст пользователей
javascript
db.users.aggregate([ { $group: { _id: null, avg_age: { $avg: "$age" } }} ])
Результат
03
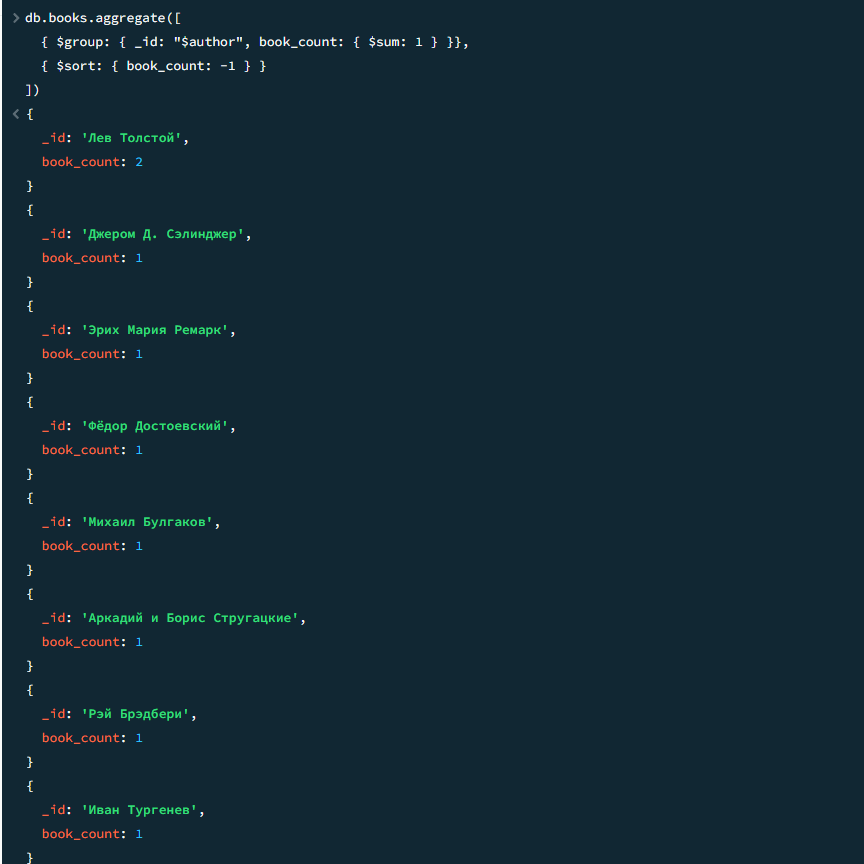
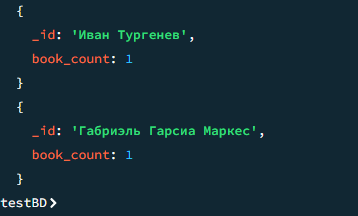
Сколько книг написал каждый автор
javascript
db.books.aggregate([ { $group: { _id: "$author", book_count: { $sum: 1 } }}, { $sort: { book_count: -1 } } ])
Результат
Результат 2
04
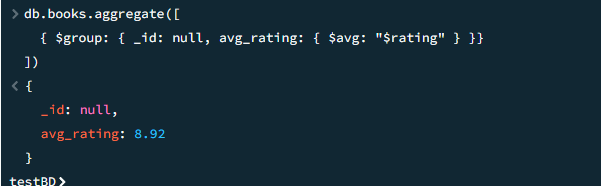
Средний рейтинг всех книг
javascript
db.books.aggregate([ { $group: { _id: null, avg_rating: { $avg: "$rating" } }} ])
Результат
05
Сколько пользователей в каждом городе
javascript
db.users.aggregate([ { $group: { _id: "$city", user_count: { $sum: 1 } }}, { $sort: { user_count: -1 } } ])
Результат
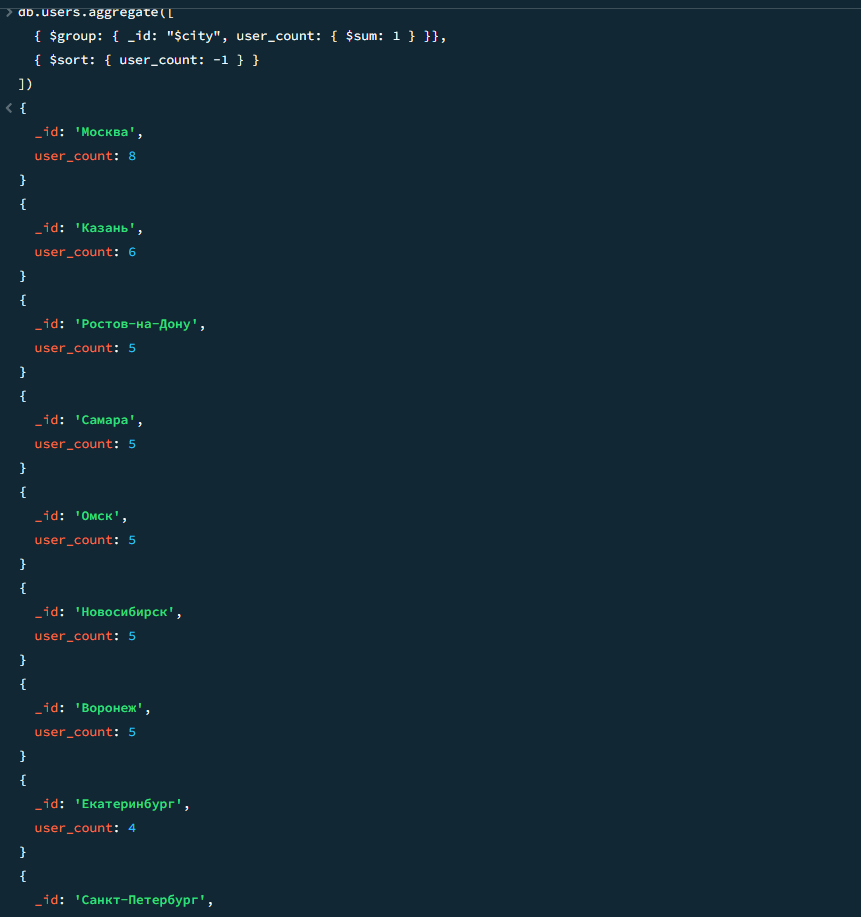
Результат 2
06
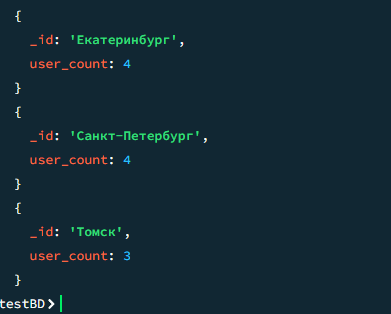
Минимальный и максимальный рейтинг книг
javascript
db.books.aggregate([ { $group: { _id: null, min_rating: { $min: "$rating" }, max_rating: { $max: "$rating" } }} ])
Результат
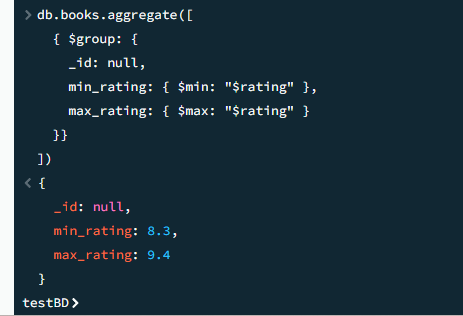
07
Общее количество взятых книг всеми пользователями
javascript
db.users.aggregate([ { $project: { books_taken: { $size: "$borrowed_books" } }}, { $group: { _id: null, total: { $sum: "$books_taken" } }} ])
Результат
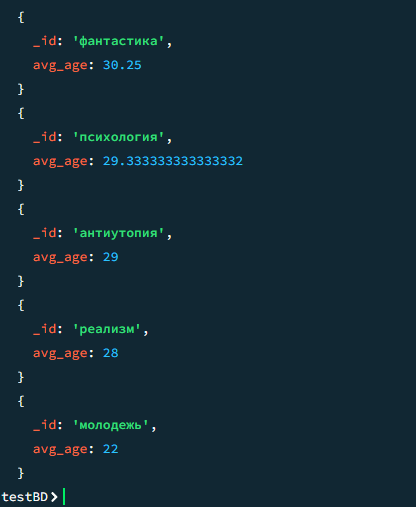
08
Средний рейтинг книг по каждому жанру
javascript
db.books.aggregate([ { $unwind: "$genres" }, { $group: { _id: "$genres", avg_rating: { $avg: "$rating" }, book_count: { $sum: 1 } }}, { $sort: { avg_rating: -1 } } ])
Результат
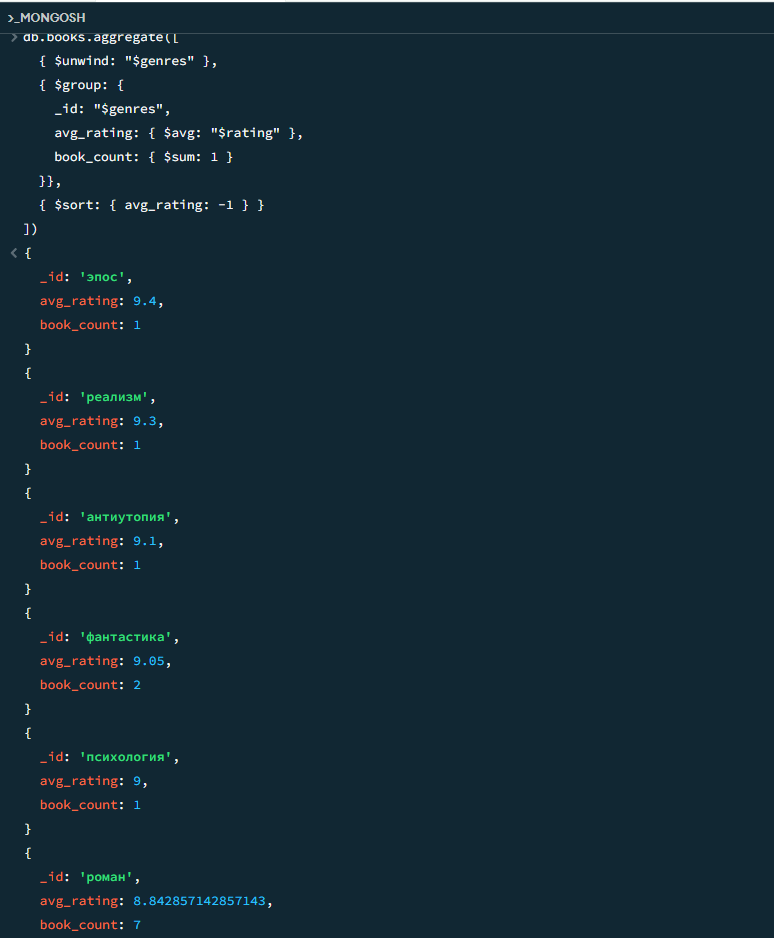
Результат 2
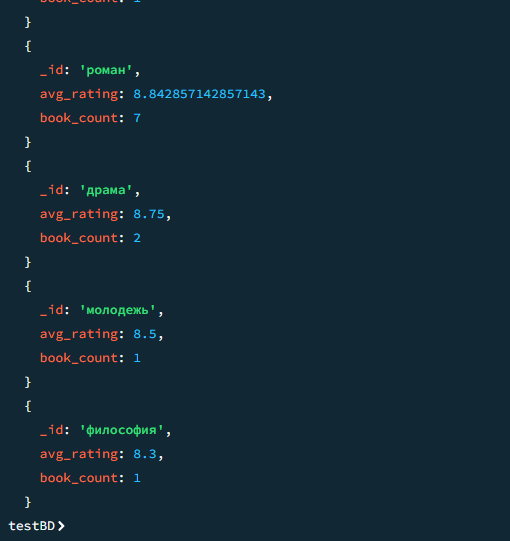
09
Среднее количество книг по городам
javascript
db.users.aggregate([ { $project: { city: 1, books_count: { $size: "$borrowed_books" } }}, { $group: { _id: "$city", avg_books: { $avg: "$books_count" } }}, { $sort: { avg_books: -1 } } ])
Результат
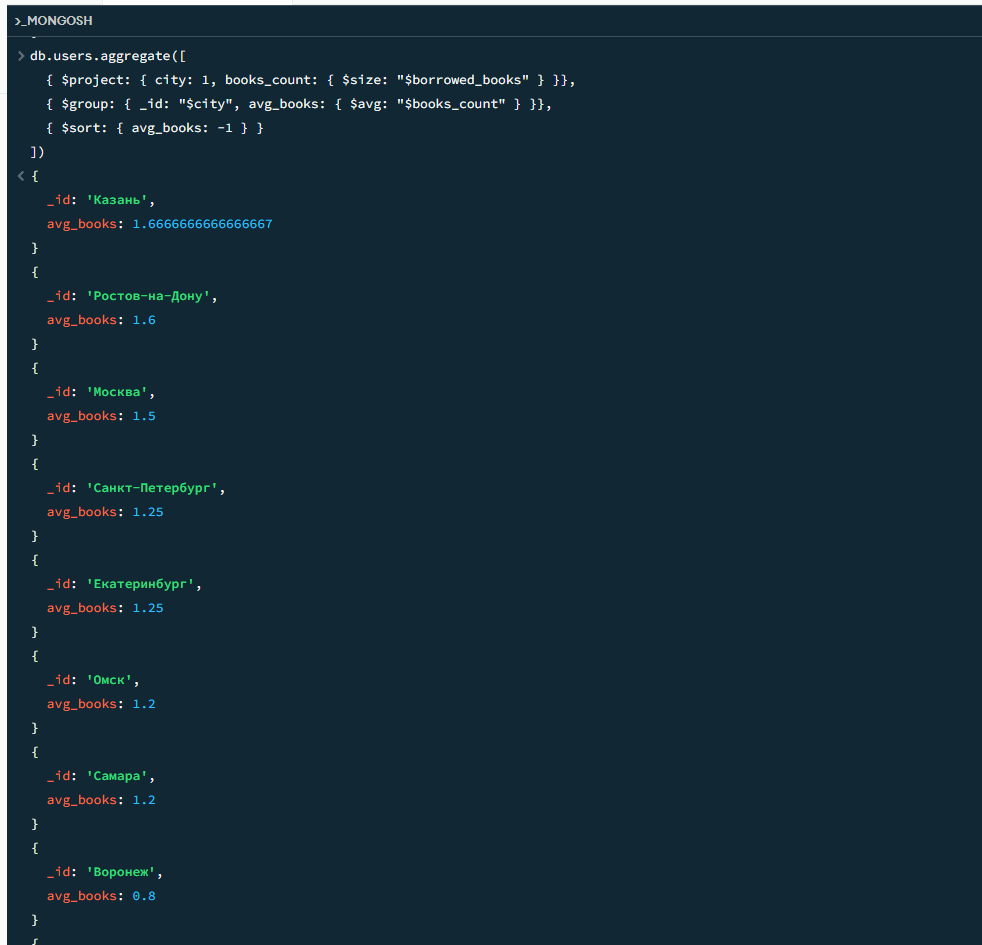
Результат 2
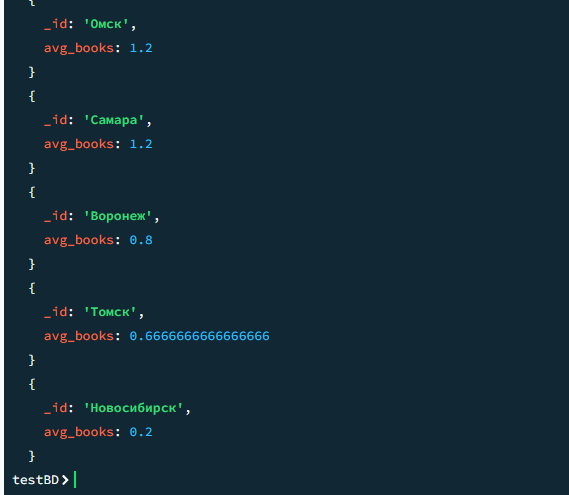
10
Автор с самым ранним годом рождения
javascript
db.authors.aggregate([ { $sort: { birth_year: 1 } }, { $limit: 1 }, { $project: { name: 1, birth_year: 1, country: 1, _id: 0 } } ])
Результат
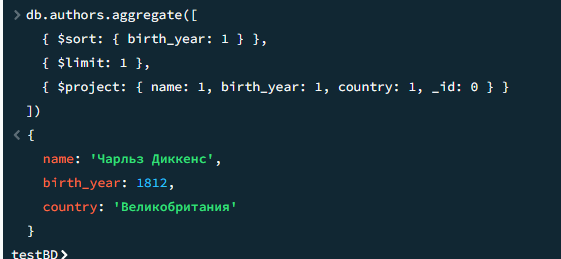
11
Топ-3 автора, чьи книги чаще всего берут
javascript
db.users.aggregate([
{ $unwind: "$borrowed_books" },
{ $lookup: {
from: "books",
localField: "borrowed_books.book_id",
foreignField: "_id",
as: "book_info"
}},
{ $unwind: "$book_info" },
{ $group: { _id: "$book_info.author", borrow_count: { $sum: 1 } }},
{ $sort: { borrow_count: -1 } },
{ $limit: 3 }
])Результат
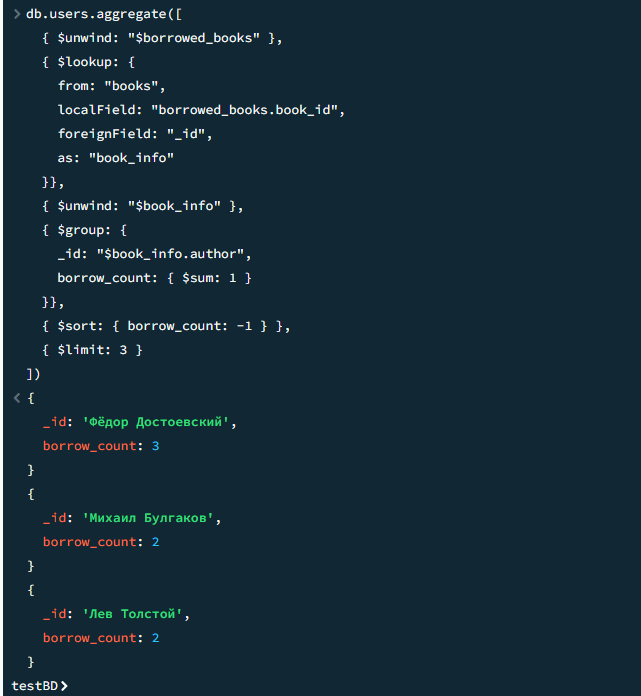
12
Сколько книг взяли после 1 октября 2025
javascript
db.users.aggregate([
{ $unwind: "$borrowed_books" },
{ $match: {
"borrowed_books.borrow_date": {
$gt: ISODate("2025-10-01T00:00:00Z")
}
}},
{ $count: "total" }
])Результат
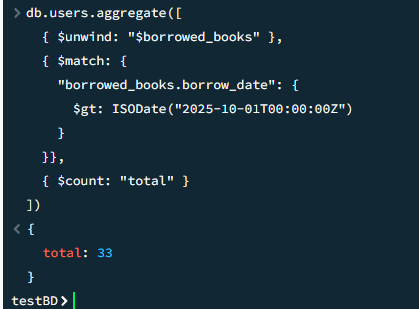
13
Средний возраст пользователей по каждому жанру
javascript
db.users.aggregate([
{ $unwind: "$borrowed_books" },
{ $lookup: {
from: "books",
localField: "borrowed_books.book_id",
foreignField: "_id",
as: "book_info"
}},
{ $unwind: "$book_info" },
{ $unwind: "$book_info.genres" },
{ $group: { _id: "$book_info.genres", avg_age: { $avg: "$age" } }},
{ $sort: { avg_age: -1 } }
])Результат
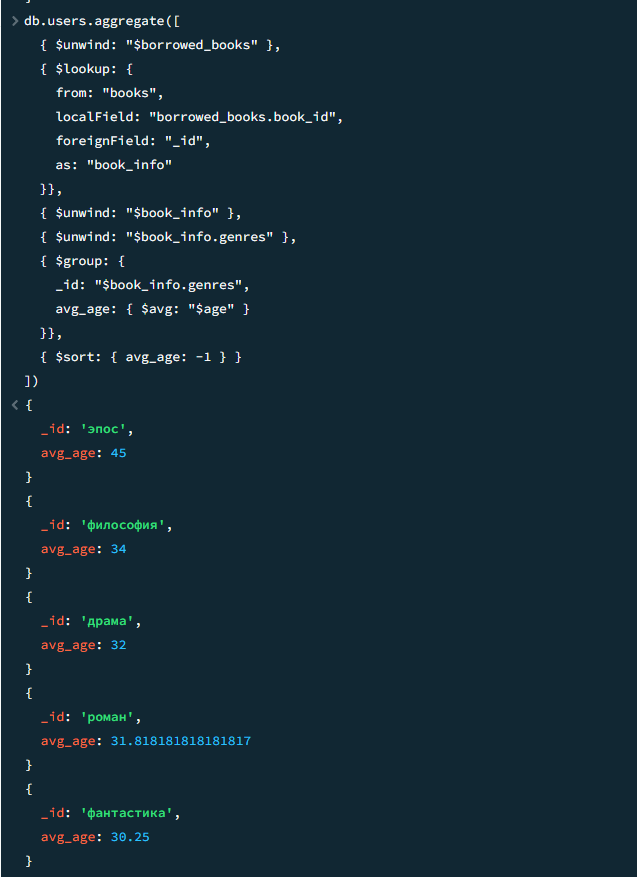
Результат 2
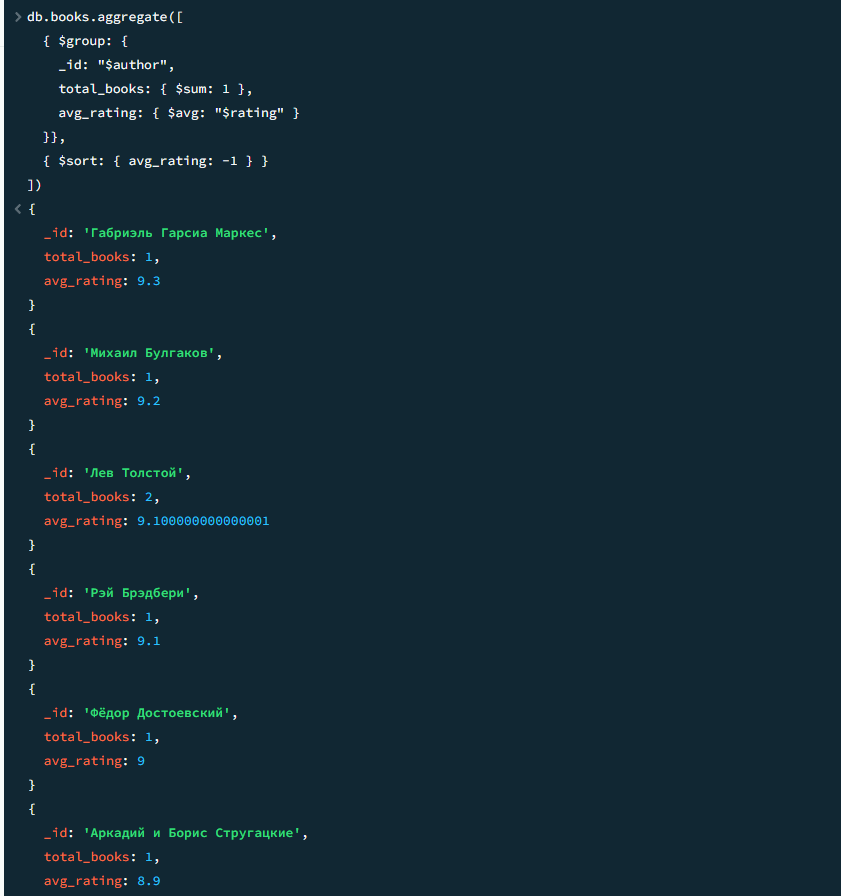
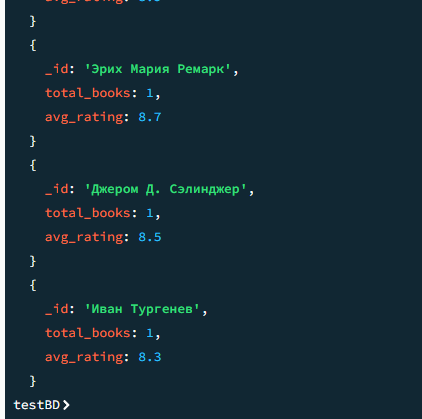
14
Общее количество книг и средний рейтинг по каждому автору
javascript
db.books.aggregate([
{ $group: {
_id: "$author",
total_books: { $sum: 1 },
avg_rating: { $avg: "$rating" }
}},
{ $sort: { avg_rating: -1 } }
])Результат
Результат 2
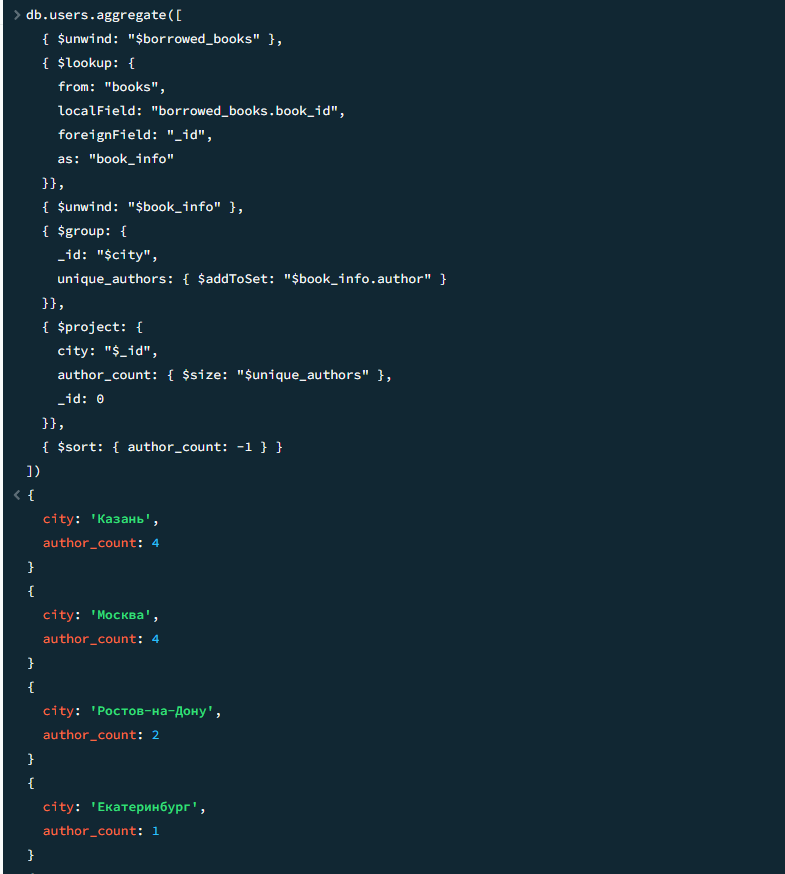
15
Сколько разных авторов читают пользователи из каждого города
javascript
db.users.aggregate([
{ $unwind: "$borrowed_books" },
{ $lookup: {
from: "books",
localField: "borrowed_books.book_id",
foreignField: "_id",
as: "book_info"
}},
{ $unwind: "$book_info" },
{ $group: {
_id: "$city",
unique_authors: { $addToSet: "$book_info.author" }
}},
{ $project: {
city: "$_id",
author_count: { $size: "$unique_authors" },
_id: 0
}},
{ $sort: { author_count: -1 } }
])Результат
Результат 2
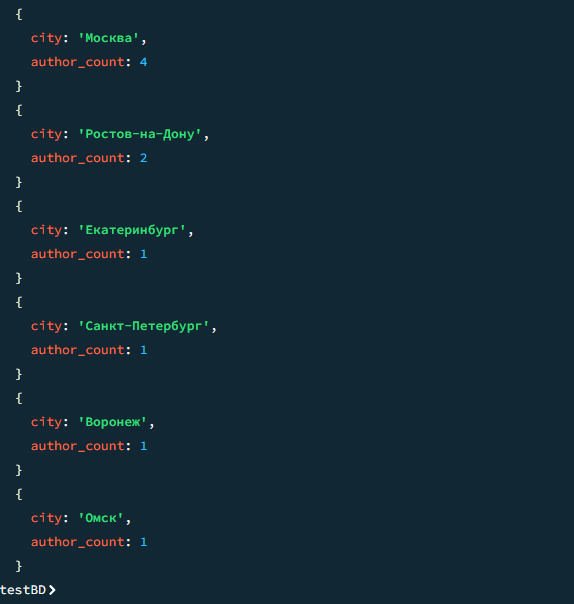
// Lab 06 · Oracle SQL Developer
JOIN-запросы, GROUP BY, подзапросы
Цель: освоить JOIN, LEFT JOIN, GROUP BY, HAVING, подзапросы на схеме HR (employees, departments, jobs, locations).
01
Список сотрудников с департаментом и должностью
sql
SELECT e.first_name, e.last_name, j.job_title, d.department_name FROM employees e JOIN jobs j ON e.job_id = j.job_id JOIN departments d ON e.department_id = d.department_id ORDER BY d.department_name;
02
Все департаменты и сотрудники (включая пустые)
sql
SELECT d.department_name, e.first_name, e.last_name FROM departments d LEFT JOIN employees e ON d.department_id = e.department_id ORDER BY d.department_name;
03
Сотрудники с городом и страной
sql
SELECT e.first_name, e.last_name, l.city, c.country_name FROM employees e JOIN departments d ON e.department_id = d.department_id JOIN locations l ON d.location_id = l.location_id JOIN countries c ON l.country_id = c.country_id ORDER BY c.country_name, l.city;
04
Средняя зарплата по каждому департаменту
sql
SELECT d.department_name, ROUND(AVG(e.salary), 2) AS avg_salary FROM employees e JOIN departments d ON e.department_id = d.department_id GROUP BY d.department_name ORDER BY avg_salary DESC;
05
Департаменты, где средняя зарплата больше 5000
sql
SELECT d.department_name, ROUND(AVG(e.salary), 2) AS avg_salary FROM employees e JOIN departments d ON e.department_id = d.department_id GROUP BY d.department_name HAVING AVG(e.salary) > 5000 ORDER BY avg_salary DESC;
06
Сотрудники с зарплатой выше средней по компании
sql
SELECT first_name, last_name, salary FROM employees WHERE salary > (SELECT AVG(salary) FROM employees) ORDER BY salary DESC;
07
Сотрудники с зарплатой выше средней по своему департаменту
sql
SELECT e.first_name, e.last_name, e.salary, e.department_id FROM employees e WHERE e.salary > ( SELECT AVG(salary) FROM employees WHERE department_id = e.department_id ) ORDER BY e.department_id;
08
Сотрудники из региона "Europe"
sql
SELECT e.first_name, e.last_name, r.region_name FROM employees e JOIN departments d ON e.department_id = d.department_id JOIN locations l ON d.location_id = l.location_id JOIN countries c ON l.country_id = c.country_id JOIN regions r ON c.region_id = r.region_id WHERE r.region_name = 'Europe';
09
Сотрудники с историей работы (job_history)
sql
SELECT DISTINCT e.first_name, e.last_name, e.employee_id FROM employees e JOIN job_history jh ON e.employee_id = jh.employee_id ORDER BY e.last_name;
10
Департамент с максимальной средней зарплатой
sql
SELECT d.department_name, ROUND(AVG(e.salary), 2) AS avg_salary FROM employees e JOIN departments d ON e.department_id = d.department_id GROUP BY d.department_name ORDER BY avg_salary DESC FETCH FIRST 1 ROWS ONLY;
11
Сотрудники с зарплатой выше любого из департамента 50
sql
SELECT first_name, last_name, salary FROM employees WHERE salary > ALL ( SELECT salary FROM employees WHERE department_id = 50 ) ORDER BY salary DESC;
12
Сотрудники и их менеджеры
sql
SELECT e.first_name || ' ' || e.last_name AS Employee, NVL(m.first_name || ' ' || m.last_name, 'No Manager') AS Manager FROM employees e LEFT JOIN employees m ON e.manager_id = m.employee_id ORDER BY Manager;
// Lab 07 · Oracle SQL Developer
Коррелированные подзапросы, EXISTS, ALL
Цель: освоить сложные подзапросы: коррелированные, EXISTS, ALL, вложенные агрегации.
01
Зарплата выше средней по департаменту И выше средней по компании
sql
SELECT e.employee_id, e.first_name, e.last_name, e.salary, e.department_id FROM employees e WHERE e.salary > ( SELECT AVG(e2.salary) FROM employees e2 WHERE e2.department_id = e.department_id ) AND e.salary > (SELECT AVG(salary) FROM employees);
02
Департаменты, где средняя зарплата выше общей средней
sql
SELECT department_id, ROUND(AVG(salary), 2) AS avg_sal FROM employees GROUP BY department_id HAVING AVG(salary) > (SELECT AVG(salary) FROM employees) ORDER BY avg_sal DESC;
03
Департамент с максимальной суммарной зарплатой
sql
SELECT department_id, SUM(salary) AS total_sal FROM employees GROUP BY department_id HAVING SUM(salary) = ( SELECT MAX(SUM(salary)) FROM employees GROUP BY department_id );
04
Сотрудники из департаментов с максимальным количеством людей
sql
SELECT e.employee_id, e.first_name, e.last_name, e.department_id FROM employees e WHERE e.department_id IN ( SELECT department_id FROM employees GROUP BY department_id HAVING COUNT(*) = ( SELECT MAX(COUNT(*)) FROM employees GROUP BY department_id ) );
05
Сотрудники с максимальной зарплатой в своём департаменте
sql
SELECT e.employee_id, e.first_name, e.last_name, e.salary, e.department_id FROM employees e WHERE e.salary = ( SELECT MAX(e2.salary) FROM employees e2 WHERE e2.department_id = e.department_id ) ORDER BY e.department_id;
06
Департаменты без сотрудников с зарплатой ниже 3000
sql
SELECT department_id FROM employees GROUP BY department_id HAVING MIN(salary) >= 3000 ORDER BY department_id;
07
Сотрудники с зарплатой выше максимальной в департаменте 50
sql
SELECT employee_id, first_name, last_name, salary FROM employees WHERE salary > ( SELECT MAX(salary) FROM employees WHERE department_id = 50 ) AND department_id <> 50 ORDER BY salary DESC;
08
Страны со средней зарплатой выше 6000
sql
SELECT co.country_name, ROUND(AVG(e.salary), 2) AS avg_sal FROM employees e JOIN departments d ON e.department_id = d.department_id JOIN locations l ON d.location_id = l.location_id JOIN countries co ON l.country_id = co.country_id GROUP BY co.country_id, co.country_name HAVING AVG(e.salary) > 6000 ORDER BY avg_sal DESC;
09
Департаменты, где сумма зарплат выше средней суммы
sql
SELECT department_id, SUM(salary) AS total_sal FROM employees GROUP BY department_id HAVING SUM(salary) > ( SELECT AVG(dept_total) FROM ( SELECT SUM(salary) AS dept_total FROM employees GROUP BY department_id ) ) ORDER BY total_sal DESC;
10
Топ-3 максимальные зарплаты компании
sql
SELECT employee_id, first_name, last_name, salary FROM employees WHERE salary IN ( SELECT DISTINCT salary FROM employees ORDER BY salary DESC FETCH FIRST 3 ROWS ONLY ) ORDER BY salary DESC;
11
Сотрудники у которых есть коллега с большей зарплатой
sql
SELECT e.employee_id, e.first_name, e.last_name, e.salary, e.department_id FROM employees e WHERE EXISTS ( SELECT 1 FROM employees e2 WHERE e2.department_id = e.department_id AND e2.salary > e.salary ) ORDER BY e.department_id, e.salary;
12
Департаменты с сотрудниками выше средней по компании
sql
SELECT DISTINCT department_id FROM employees WHERE salary > (SELECT AVG(salary) FROM employees) ORDER BY department_id;
13
Максимальная зарплата в департаменте через NOT EXISTS
sql
SELECT e.employee_id, e.first_name, e.last_name, e.salary, e.department_id FROM employees e WHERE NOT EXISTS ( SELECT 1 FROM employees e2 WHERE e2.department_id = e.department_id AND e2.salary > e.salary ) ORDER BY e.department_id;
14
Департаменты, где ВСЕ сотрудники получают больше 3000
sql
SELECT department_id FROM employees GROUP BY department_id HAVING MIN(salary) > 3000 ORDER BY department_id;
15
Сотрудники из департаментов со средней выше общей
sql
SELECT e.employee_id, e.first_name, e.last_name, e.salary, e.department_id FROM employees e WHERE e.department_id IN ( SELECT department_id FROM employees GROUP BY department_id HAVING AVG(salary) > (SELECT AVG(salary) FROM employees) ) ORDER BY e.department_id;
16
Сотрудники с зарплатой выше всех из других департаментов
sql
SELECT e.employee_id, e.first_name, e.last_name, e.salary, e.department_id FROM employees e WHERE e.salary > ALL ( SELECT e2.salary FROM employees e2 WHERE e2.department_id <> e.department_id ) ORDER BY e.salary DESC;
17
Департаменты с сотрудником с максимальной зарплатой компании
sql
SELECT DISTINCT e.department_id FROM employees e WHERE EXISTS ( SELECT 1 FROM employees e2 WHERE e2.department_id = e.department_id AND e2.salary = (SELECT MAX(salary) FROM employees) );
18
Сотрудники с историей работы и зарплатой выше средней по прошлым
sql
SELECT e.employee_id, e.first_name, e.last_name, e.salary FROM employees e WHERE EXISTS ( SELECT 1 FROM job_history jh WHERE jh.employee_id = e.employee_id ) AND e.salary > ( SELECT AVG(e2.salary) FROM employees e2 JOIN job_history jh ON jh.employee_id = e2.employee_id WHERE jh.employee_id = e.employee_id );
19
Страны, где нет ни одного департамента без сотрудников
sql
SELECT co.country_id, co.country_name FROM countries co WHERE NOT EXISTS ( SELECT 1 FROM locations l JOIN departments d ON d.location_id = l.location_id WHERE l.country_id = co.country_id AND NOT EXISTS ( SELECT 1 FROM employees e WHERE e.department_id = d.department_id ) );
20
Сотрудники с зарплатой выше средней каждого департамента (через ALL)
sql
SELECT e.employee_id, e.first_name, e.last_name, e.salary FROM employees e WHERE e.salary > ALL ( SELECT AVG(salary) FROM employees GROUP BY department_id ) ORDER BY e.salary DESC;